Le migliori pratiche di Lenovo in risposta alla gestione degli errori di memoria non correggibili Intel® sui processori Xeon® Scalable di Gen 3, Gen 1, Gen 2 o SKU "H"
Le migliori pratiche di Lenovo in risposta alla gestione degli errori di memoria non correggibili Intel® sui processori Xeon® Scalable di Gen 3, Gen 1, Gen 2 o SKU "H"
Le migliori pratiche di Lenovo in risposta alla gestione degli errori di memoria non correggibili Intel® sui processori Xeon® Scalable di Gen 3, Gen 1, Gen 2 o SKU "H"
Descrizione
Lenovo è stato il numero 1 in affidabilità per 7 anni e desidera informare i propri clienti delle riduzioni inerenti a tutti i sistemi industriali che utilizzano determinate generazioni di Intel® processori, che hanno ridotto generazionalmente le capacità di controllo e correzione degli errori disponibili per i fornitori di sistemi OEM. Una combinazione di errori di memoria DDR e cambiamenti architettonici presenti nella logica di gestione degli errori di memoria correttivi, sui processori Xeon® Scalable di Gen 1 (nome in codice "Skylake"), Gen 2 Xeon® Scalable (nome in codice "Cascade Lake") e Gen 3 Xeon® Scalable (nome in codice "Cooper Lake-6") può comportare un tasso più elevato di errori di memoria non correggibili a runtime (UCE) rispetto alle generazioni precedenti di hardware. Questo è dovuto ai cambiamenti implementati nel Single Device Data Correction (SDDC). SDDC è una funzionalità fondamentale di Intel RAS (Affidabilità, Disponibilità, Manutenibilità) disponibile su tutte le piattaforme. A causa di questi cambiamenti architettonici e degli errori di memoria DIMM, c'è una differenza nel modo in cui gli errori verranno corretti tra la generazione precedente di processori e la famiglia di processori Xeon® Scalable. Per ulteriori informazioni da Intel® si prega di consultare Come posso migliorare la gestione della memoria con i processori Xeon® Scalable di 1ª, 2ª o 3ª generazione Intel®. Questo articolo si concentrerà su strategie chiave per mitigare gli errori DDR non correggibili che a volte portano alla terminazione delle applicazioni o ai crash dei server.
Il problema può essere identificato osservando eventi di errore di memoria non correggibili o eventi di errore di controllo macchina segnalati da Lenovo ThinkSystem o prodotto ThinkAgile:
FQXSFMA0002M : È stato rilevato un errore di memoria non correggibile su DIMM [arg1] all'indirizzo [arg2]. [arg3] FQXSFPU0062F : Si è verificato un errore di sistema non correggibile nel processore [arg1] core [arg2] MC bank [arg3] con MC Status [arg4], MC Address [arg5] e MC Misc [arg6]. FQXSFPU0027N : Si è verificato un errore recuperabile non corretto nel sistema sul processore [arg1] core [arg2] MC bank [arg3] con MC Status [arg4], MC Address [arg5] e MC Misc [arg6].
(dove XCC = Lenovo XClarity Controller)
Ogni riga qui sotto si espanderà con ulteriori informazioni cliccando sulla freccia sul lato destro del titolo
Sistemi Applicabili
Il sistema può essere uno dei seguenti server Lenovo: 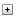
Best Practices
ThinkSystem firmware supporta le funzionalità RAS offerte dai processori Intel® Scalable che possono ridurre notevolmente la frequenza degli errori DDR non correggibili. Pertanto, gli amministratori di sistema e gli operatori dovrebbero sfruttare le funzionalità RAS supportate dai processori Xeon® Scalable di Gen1/Gen2/Gen3 Intel® e pianificare test di memoria di routine disponibili all'interno di LXPM. Le migliori pratiche delineate in questo articolo dovrebbero essere applicabili alle future generazioni di CPU che supporteranno la memoria oltre la generazione DDR4 offerta con i processori Xeon® Scalable di Gen 3 (nome in codice "Cooper Lake-6").
Mantenere la validità del codice
Aggiornare i server ThinkSystem di produzione al firmware rilasciato nel primo trimestre del 2021 o superiore, il che garantirà che tutte le correzioni di firmware note di Intel e Lenovo siano state applicate. Questo può essere fatto navigando all'URL del Portale di Supporto Lenovo: https://support.lenovo.com e selezionando il Gruppo Prodotto appropriato, il tipo di Sistema, il nome del Prodotto, il tipo di macchina del Prodotto e il sistema operativo.
Pianificare lo screening della memoria on-target
Pianificare di eseguire i Test Avanzati della Memoria LXPM almeno ogni 6 mesi e prima del nuovo deployment del sistema o della manutenzione del sistema, vedere URL: HT511056 - Il Test Avanzato della Memoria LXPM riduce gli errori DIMM. I seguenti passaggi dovrebbero essere utilizzati quando si considera questa opzione.
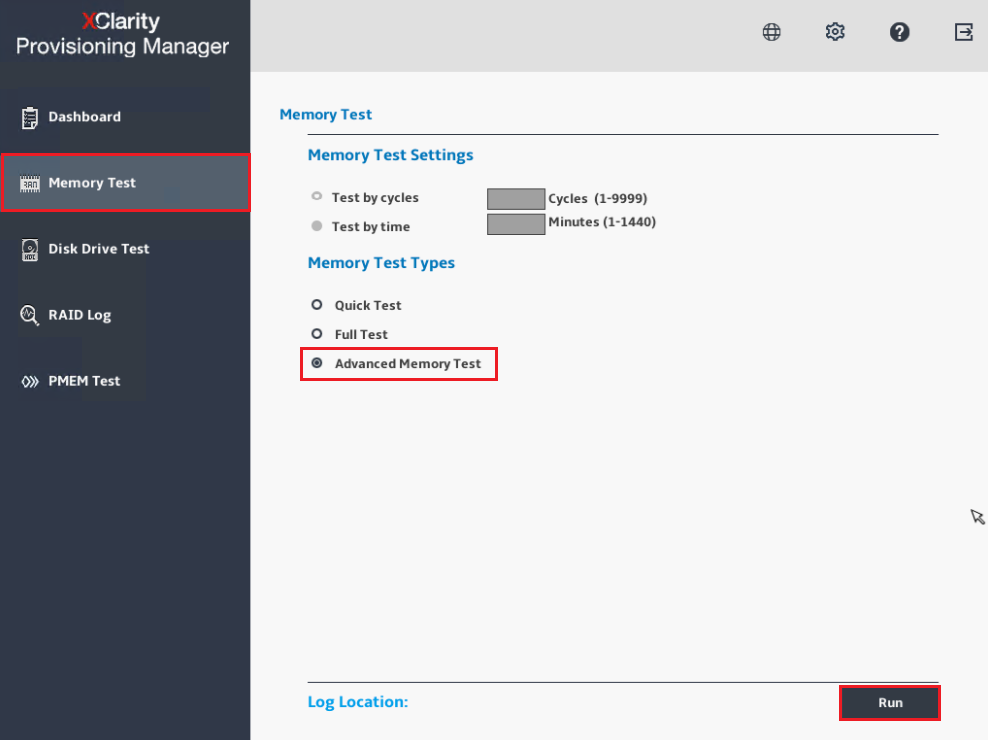
- Mantenere il firmware di sistema (UEFI & BMC/XCC) aggiornato: per i migliori risultati, assicurarsi che il sistema target stia eseguendo il firmware più recente o lo stack di firmware rilasciato dopo il primo trimestre del 2021.
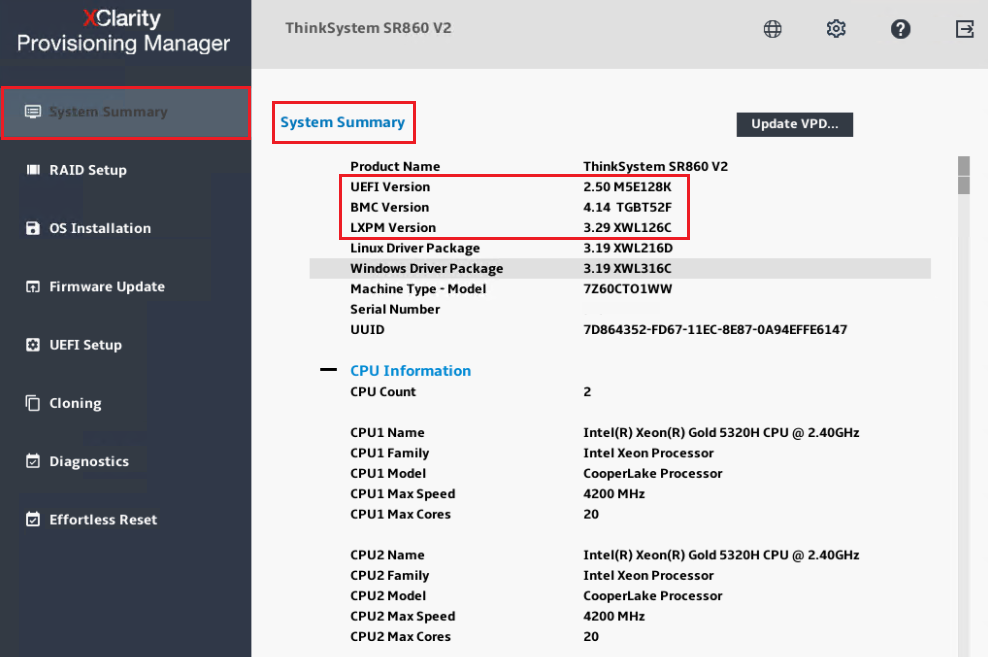
- Controllare Informazioni di Sistema durante POST o selezionare Riepilogo di Sistema per controllare le informazioni sul firmware del sistema:
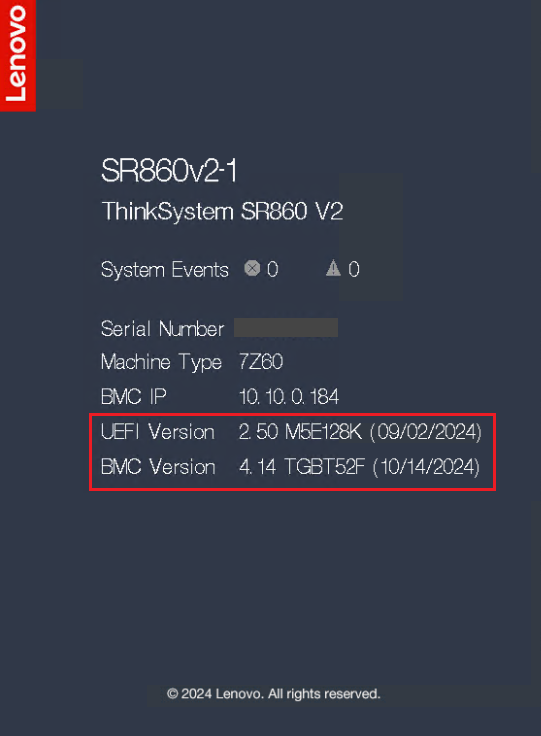
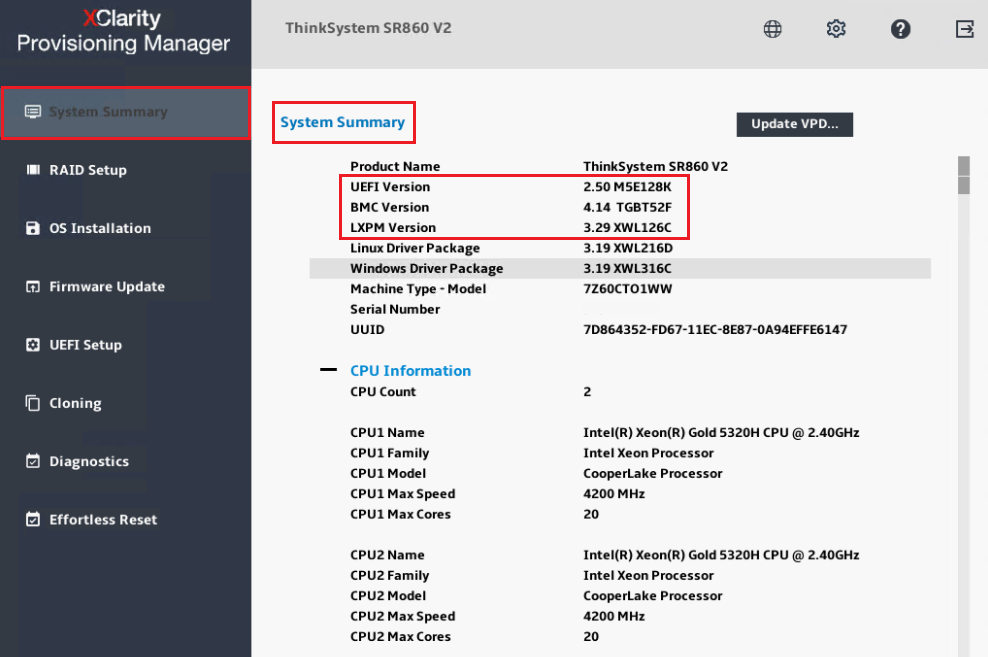
- Controllare Informazioni di Sistema durante POST o selezionare Riepilogo di Sistema per controllare le informazioni sul firmware del sistema:
- Quando si utilizza il metodo della Command Line Interface (CLI) fare riferimento ai comandi qui sotto:
Per abilitare l'AMT, eseguire:
OneCli.exe config set Memory.MemoryTest Enable --imm xcc_user_id:xcc_password@xcc_external_ip OneCli.exe config set Memory.AdvMemTestOptions 0xF0000 --override --imm xcc_user_id:xcc_password@xcc_external_ip
Per disabilitare l'AMT, eseguire:
OneCli.exe config set Memory.MemoryTest Automatic --imm xcc_user_id:xcc_password@xcc_external_ip OneCli.exe config set Memory.AdvMemTestOptions 0 --override --imm xcc_user_id:xcc_password@xcc_external_ip
- Quando si utilizza l'interfaccia grafica (GUI) accendere il server e premere F1 per entrare nel menu di configurazione ThinkSystem UEFI, XClarity Provisioning Manager.
- Selezionare l'opzione Diagnostica dal menu a sinistra.
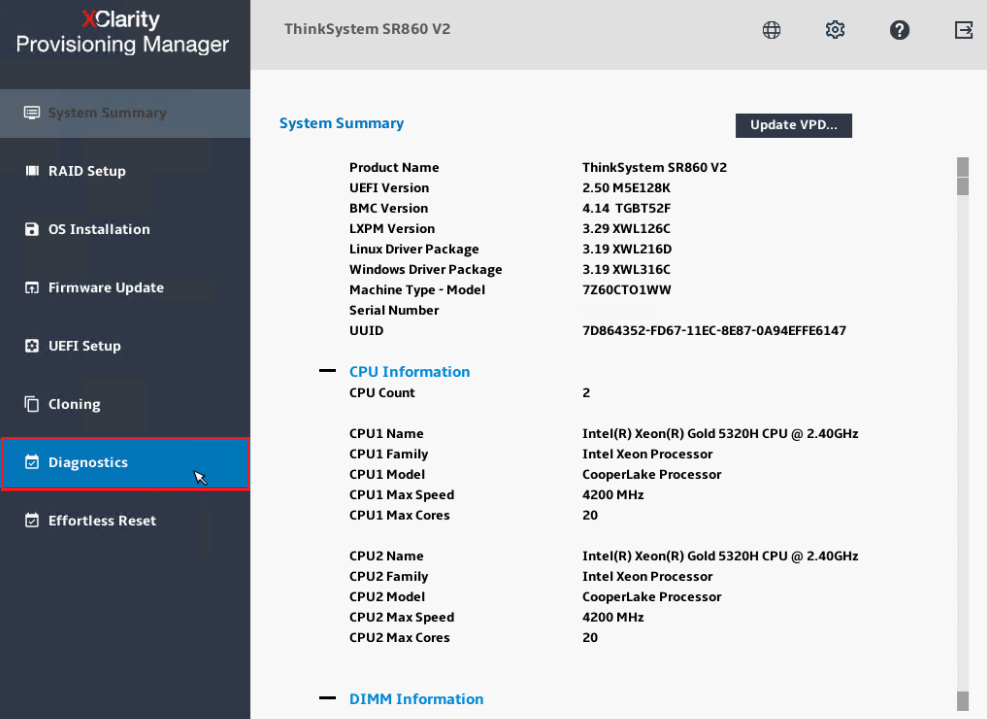
- Selezionare Esegui Diagnostica dalla schermata Diagnostica.
_20250115070109778.png)
- Selezionare Test di Memoria dal Dashboard.
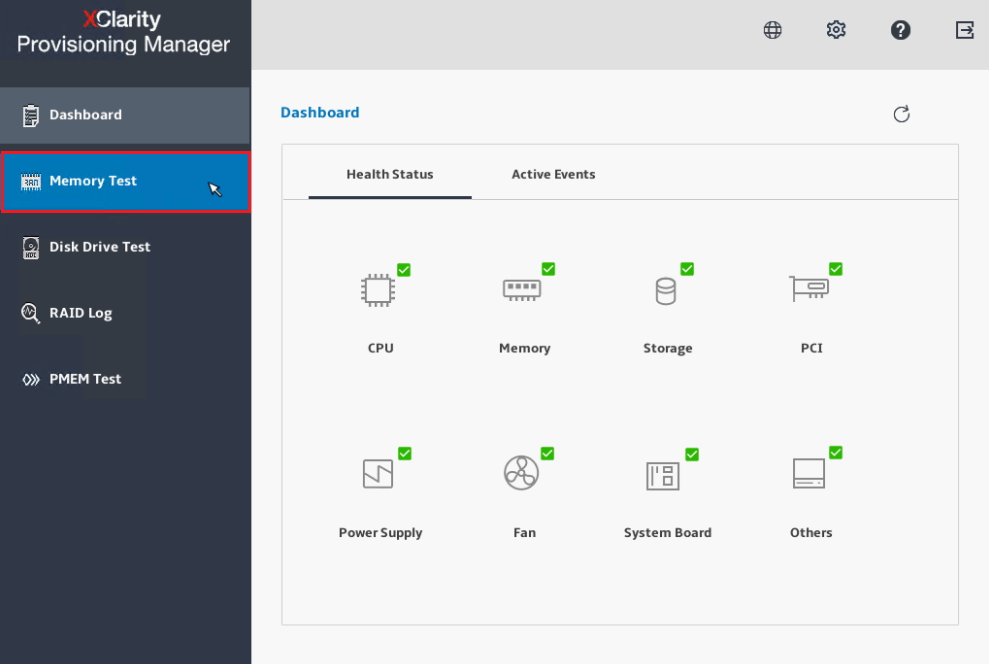
- Selezionare Test Avanzato della Memoria dal menu Test di Memoria.
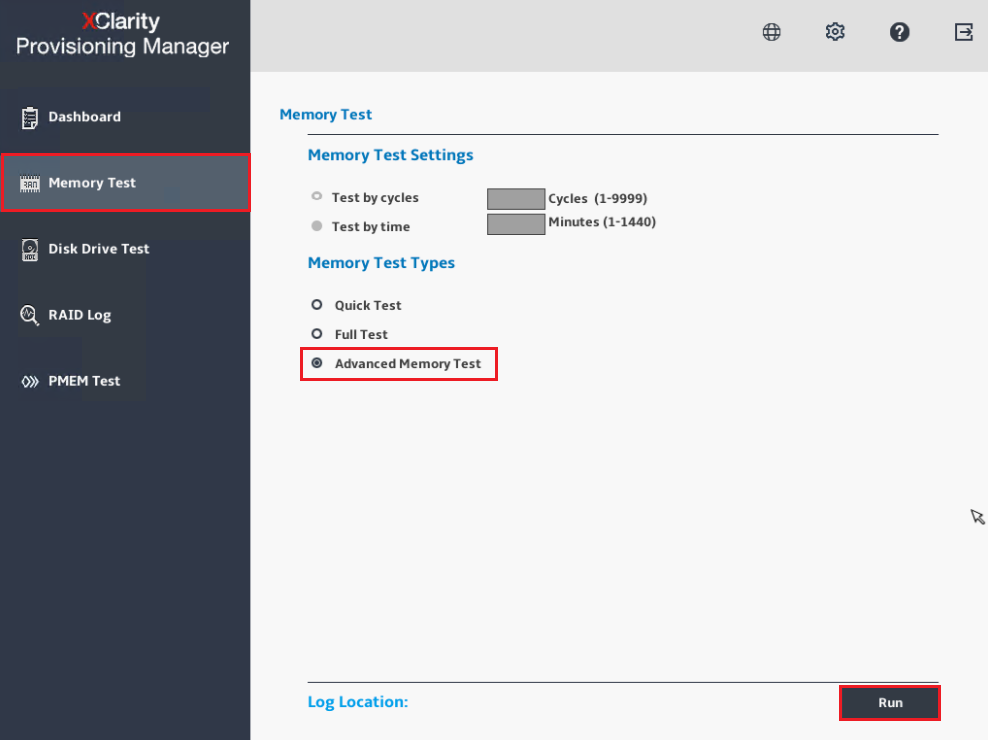

- Dopo che il Test Avanzato della Memoria (AMT) è stato selezionato, il sistema si riavvierà e il test di memoria verrà eseguito durante UEFI POST. Questo test è molto simile al test di livello di produzione e non può essere disabilitato fino al completamento di un intero ciclo di test. Riavviare il sistema nel mezzo dell'operazione di test riavvierà il test di memoria dall'inizio, a meno che la batteria CMOS non venga rimossa. Il sistema tornerà alla Pagina Diagnostica e fornirà un'interfaccia per salvare i log di sistema quando si trova nella Configurazione Grafica del Sistema.
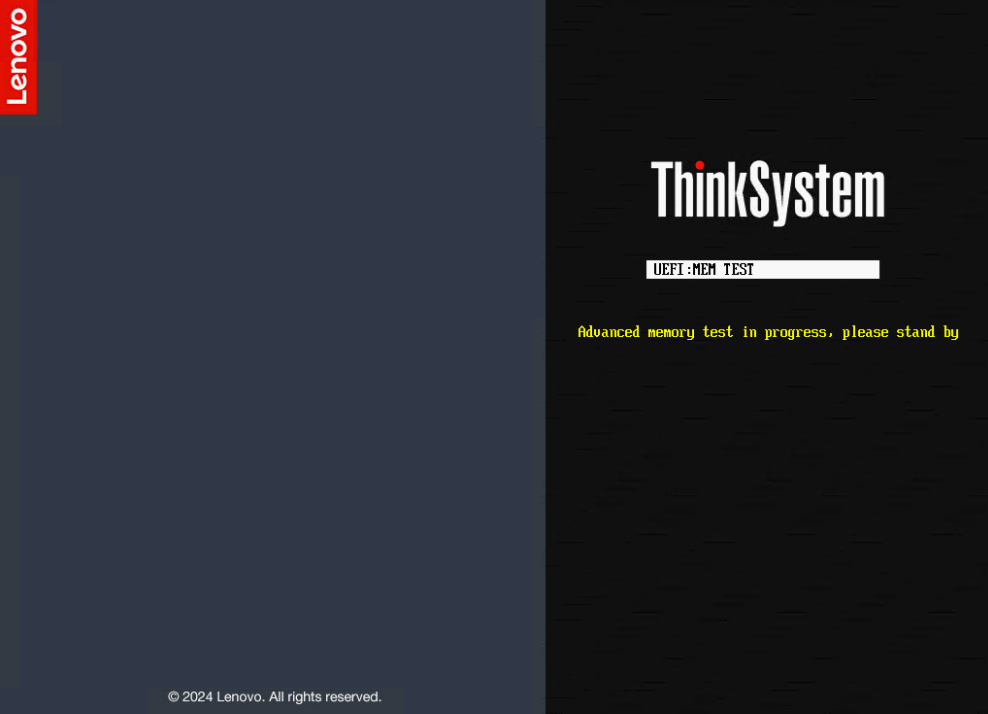
- Il tempo necessario per completare il test varia da sistema a sistema. Dopo il completamento del test, il sistema tornerà alla pagina di test di memoria in LXPM con un messaggio per inserire un USB disco nel sistema per salvare il file di log. Inserire un USB disco nel sistema e fare clic su Riprova per continuare.
- Se un utente desidera saltare l'opzione per salvare il log del test, allora la configurazione del F1 System Setup deve essere impostata per funzionare in Modalità Testo.
Comando Redfish per abilitare/disabilitare AMT
{ "Attributes": { "Memory_MemoryTest": "Enabled", "Memory_AdvMemTestOptions": 983040 } }Nota: Per ulteriori dettagli, si prega di fare riferimento a Test Avanzato della Memoria su Server XeonBased ThinkSystem.
Abilitare il Recupero degli Errori di Macchina (MCA) e il Recupero Locale degli Errori di Macchina (LMCE)
Il Recupero MCA consente al sistema operativo di decidere se l'errore può essere recuperato dal sistema operativo senza interrompere il sistema; per ulteriori informazioni su questa funzionalità RAS, si prega di consultare la sezione dettagli. Per informazioni più dettagliate sul Recupero MCA, si prega di consultare la sezione Informazioni Aggiuntive.
I seguenti passaggi dovrebbero essere utilizzati quando si considera questa opzione.
- Quando si utilizza il metodo CLI selezionare “AdvancedRAS.MachineCheckRecovery=Enable”. Questa funzionalità è abilitata per impostazione predefinita nella configurazione UEFI.
- Quando si utilizza il metodo GUI:
- Accendere il server.
- Premere F1 per entrare nella Configurazione di Sistema, LXPM.
- Dal menu di navigazione a sinistra, selezionare Impostazioni di Sistema→ Recupero e RAS come mostrato di seguito.
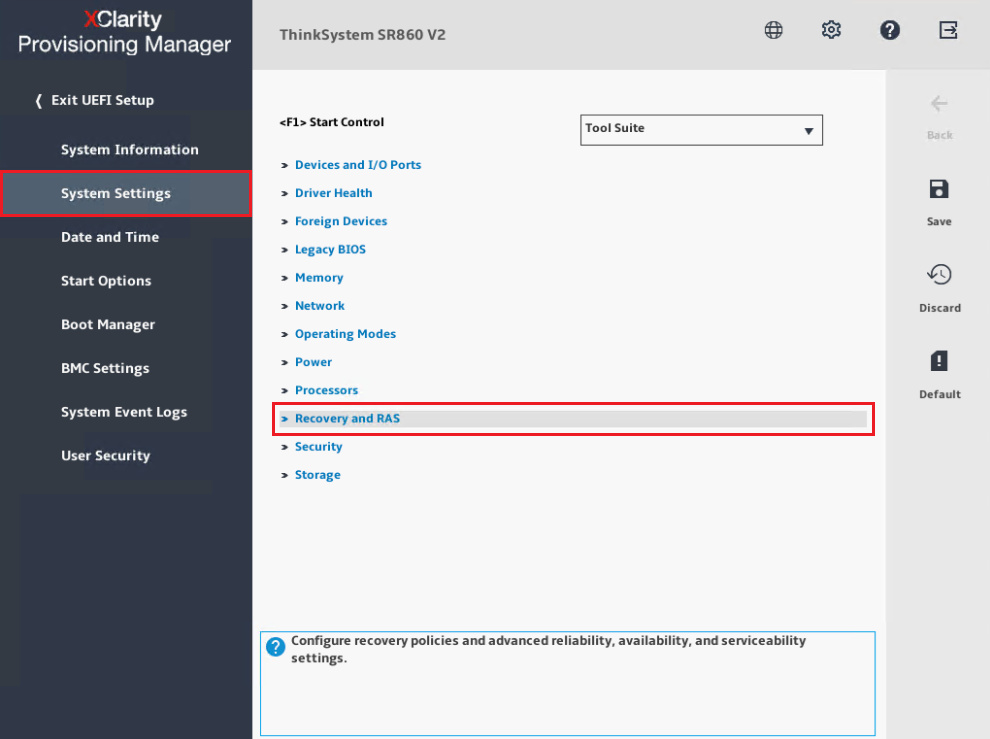
- Selezionare RAS Avanzato.
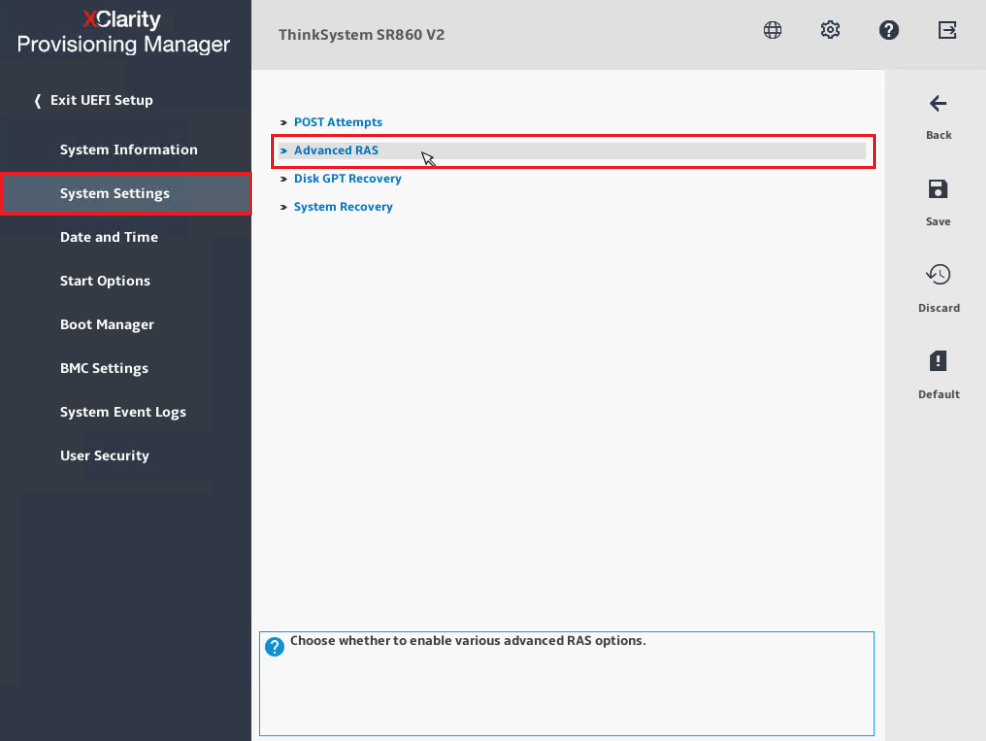
- Abilitare Recupero degli Errori di Macchina.
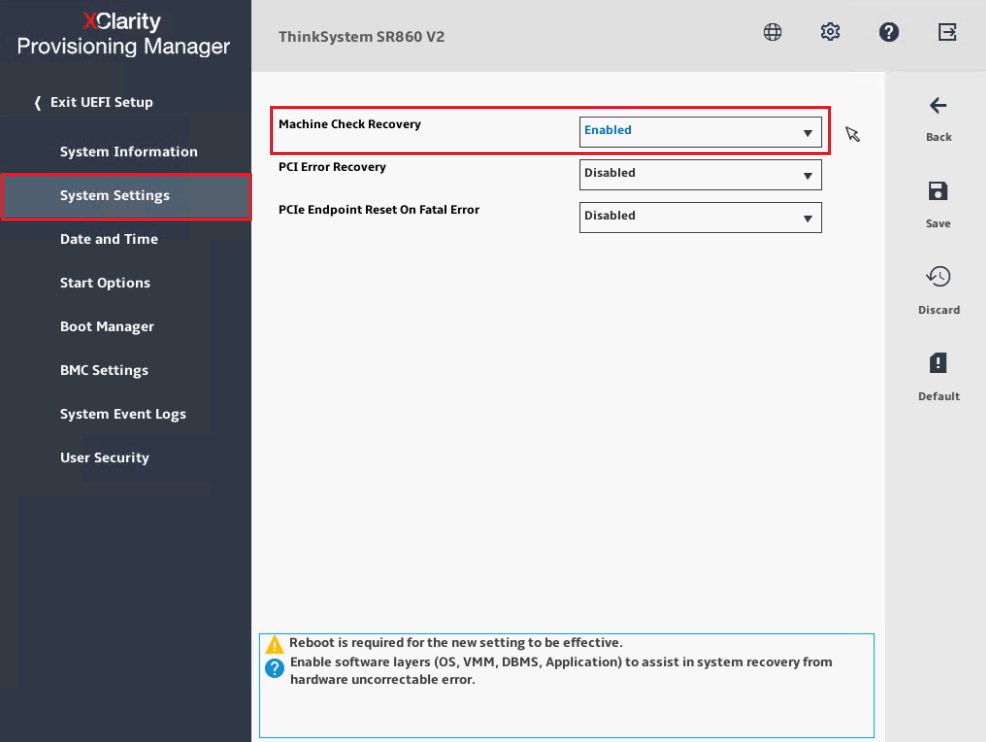
Nota: Il recupero MCA e il Recupero Locale degli Errori di Macchina (LMCE) dipendono dal supporto del sistema operativo, quindi consultare il proprio fornitore di sistema operativo per la capacità MCA e LMCE, poiché ogni fornitore di sistema operativo adotta funzionalità RAS utilizzando i propri cicli di rilascio. Il firmware della piattaforma basata su Lenovo abilita il recupero basato su LMCE per impostazione predefinita, ma questa impostazione non è esposta allo Spazio Utente nella Configurazione UEFI. I vantaggi di LMCE rispetto a MCE sono discussi nel seguente documento: Gestione delle Eccezioni Locali di Macchina in Linux.
Windows: Per una descrizione dettagliata di come Windows utilizza le funzionalità RAS, consultare la Windows Guida alla Progettazione dell'Architettura degli Errori Hardware (WHEA). Fare riferimento alla sezione “Informazioni Aggiuntive” per l'elenco delle funzionalità RAS supportate dal sistema operativo.
VMware: Il recupero degli errori di macchina è supportato dal kernel nella versione ESXi 5 e superiori. Fare riferimento alla sezione “Informazioni Aggiuntive” per l'elenco delle funzionalità RAS supportate dal sistema operativo.
Inoltre, l'utente dovrebbe approfittare del Recupero basato su Local Machine Check (LMCE) che è abilitato per impostazione predefinita nella versione ESXi 7.0, vedere Lenovo ThinkSystem Server con supporto per il Modulo di Memoria Persistente Optane™ DC Intel®
Per i Lenovo ThinkSystem SR850P e SR850, a causa di una nota limitazione hardware, è necessario abilitare il flag di avvio del kernel “useLMCE” per supportare il recupero degli errori di macchina locale con le versioni ESXi 6.7 U2 e superiori.
- Per abilitare il recupero MCE locale su un sistema ESXi 6.7 U2:
Nella console ESXi, eseguire questi due comandi esxcli per impostare l'opzione di avvio del kernel, impostare LMCE su TRUE, quindi riavviare il sistema affinché le modifiche abbiano effetto.esxcli system settings kernel set -s useLMCE -v TRUE /sbin/reboot
Dopo un riavvio, verificare che l'impostazione sia stata applicata eseguendo questo comando:esxcli system settings kernel list -o “useLMCE”
Linux: Fare riferimento alla sezione “Informazioni Aggiuntive” per l'elenco delle funzionalità RAS supportate dal sistema operativo. Elenco del supporto del kernel per il recupero MCA da parte dei principali fornitori di Linux:

Fonte: Pratica di Ingegneria per Ridurre il Tasso di Crash dei Server da Errori DDR Non Correggibili (UCE) nei Data Center Cloud Iperscalabili, vedere Pratica di Ingegneria per Ridurre il Crash dei Server
Mantenere Abilitato il Patrol Scrub
Per evitare un accumulo di errori soft che possono trasformarsi in errori non correggibili (UCE), il chipset Intel ha un motore di scrubbing della memoria integrato. Legge i dati da ciascuna posizione di memoria DDR e corregge gli errori di bit (se presenti) con un codice di correzione degli errori (ECC), quindi scrive i dati corretti nella stessa posizione. Il patrol scrubbing è impostato per un intervallo di 24 ore in cui ogni indirizzo viene controllato durante questo periodo.
- Quando si utilizza il metodo CLI selezionare “Memory.PatrolScrub=Enable”. Questa funzionalità è abilitata per impostazione predefinita nella configurazione UEFI.
Disabilitare il Cold Boot Fast
Forzare l'addestramento della memoria ad ogni riavvio disabilitando il Cold Boot Fast, questo aumenterà il tempo di avvio del sistema durante il POST. Lo scopo del Cold Boot Fast è saltare l'addestramento della memoria se non è stata rilevata alcuna modifica di configurazione negli ultimi 90 giorni, il che migliora il tempo di avvio del sistema. Disabilitare il Cold Boot Fast consente di riaddestrare l'interfaccia di memoria, compensando eventuali cambiamenti significativi nelle condizioni ambientali.
- Quando si utilizza il metodo CLI selezionare “Memory.ColdBootFast=Disable”.
- Questa funzionalità è abilitata per impostazione predefinita nella configurazione UEFI.
Sfruttare il Post Package Repair
Questa è una funzionalità guidata dall'industria definita da JEDEC per abilitare il Boot Time Post Package Repair (PPR) per sostituire una riga, all'interno di un DRAM, che si determina essere difettosa. L'intento della funzionalità è ridurre le sostituzioni DIMM sul campo a causa della presenza di celle difettose. Durante il runtime, un DIMM che presenta difetti correggibili può essere programmato per avere un PPR eseguito in un ciclo di avvio successivo. Il DRAM che presenta il difetto, all'interno del DIMM, avrà la riga sostituita internamente da una riga di riserva, all'interno dello stesso DRAM. Questo processo di fusione correttiva PPR è permanente.
Ad esempio, se il sistema ha segnalato un PFA durante il runtime, allora al successivo ciclo di riavvio, l'UEFI tenterà una riparazione. Questo sarà indicato da un messaggio “Auto-Riparazione” nel registro eventi, e dopo il completamento, il PFA sarà disattivato.
Impostare la Modalità Operativa del Sistema su Massima Prestazione
In alcune situazioni, è stato osservato che disabilitare le politiche di gestione dell'alimentazione nel sistema UEFI e nel client vSphere ha risolto errori di bus 'Non Correttibili' intermittenti o riavvii del sistema e errori di memoria.
- Quando si utilizza il metodo CLI selezionare “OperatingModes.ChooseOperatingMode=Massima Prestazione".
- Per abilitare la Massima Prestazione utilizzando il metodo CLI, eseguire:
OneCli.exe config set OperatingModes.ChooseOperatingMode "Massima Prestazione" --imm xcc_user_id:xcc_password@xcc_external_ip
Per riferimento vedere Ottimizzazione del sistema per VMware su server x86 e ThinkSystem, vedere Ottimizzazione del sistema per VMware su server x86 e ThinkSystem
Per riferimento vedere Impostazioni UEFI consigliate - Lenovo sistemi ThinkAgile HX, vedere URL: Impostazioni UEFI consigliate
Abilitare il Mirroring dell'Intervallo di Indirizzi / Mirroring Parziale della Memoria
Il Mirroring dell'Intervallo di Indirizzi è una funzionalità RAS disponibile sulle piattaforme della famiglia Intel Xeon Scalable che consente un controllo granulare su quanto memoria è allocata per la ridondanza, vedere la sezione dettagli per ulteriori informazioni. I seguenti passaggi dovrebbero essere utilizzati quando si considera questa opzione. Per informazioni più dettagliate sul Mirroring dell'Intervallo di Indirizzi, si prega di consultare la sezione Informazioni Aggiuntive.
- Quando si utilizza il metodo CLI selezionare “Memory.MirrorMode=Parziale”, “Memory.Mirrorbelow4GB=Abilita”
- Quando il Mirroring dell'Intervallo di Indirizzi è abilitato, il contenuto della memoria sarà duplicato sul DIMM remoto nella partizione. Ciò significa che non tutta la memoria di sistema sarà disponibile per il sistema operativo. Ad esempio, con il mirroring parziale abilitato, l'UEFI dedicherà 36 GB di memoria fissa al mirror per ogni processore fisico.
- Seguire i passaggi seguenti per abilitare la Modalità di Mirror Parziale per la ridondanza della memoria:
- Accendere il server.
- Premere il tasto F1 per entrare in LXPM:
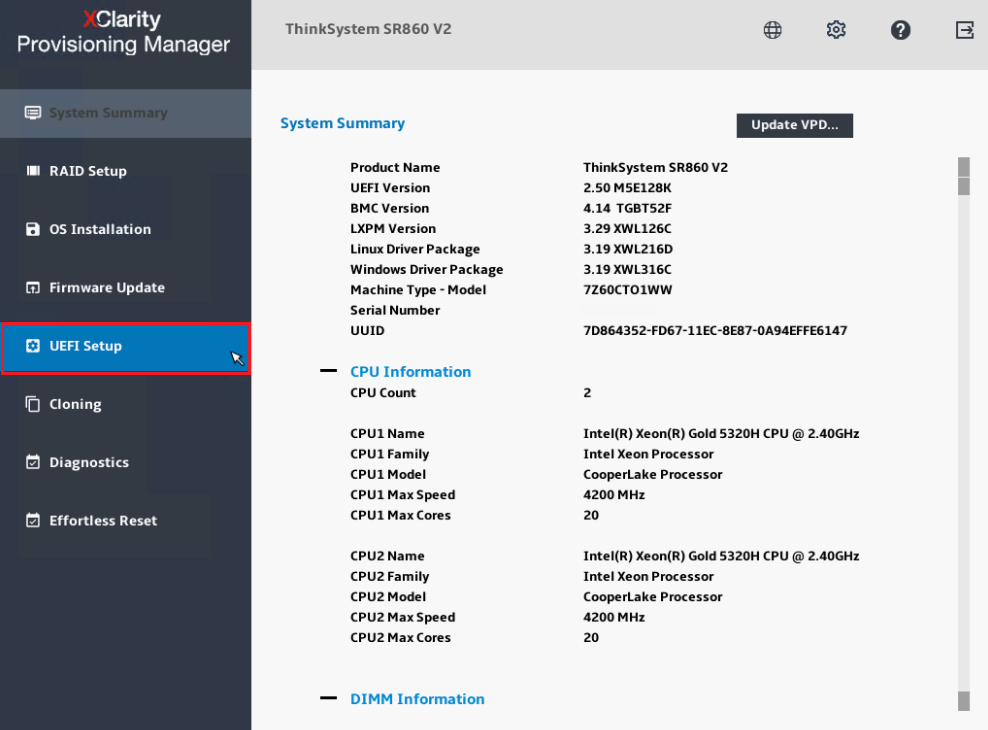
- Selezionare Configurazione UEFI nel menu di navigazione a sinistra.
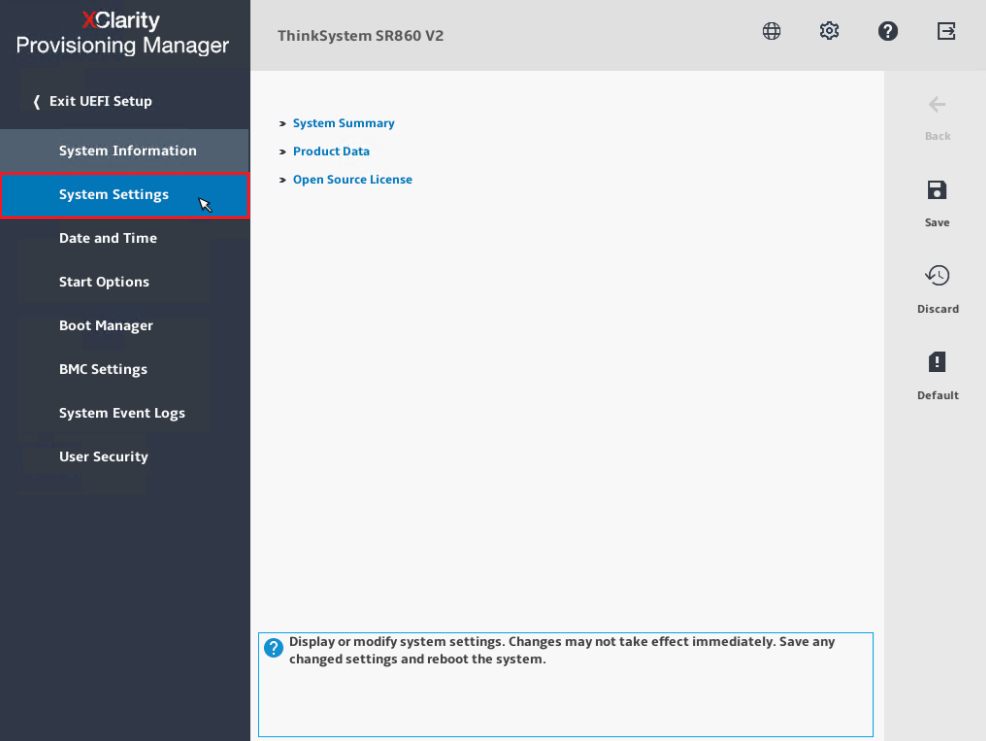
- Selezionare Impostazioni di Sistema.
- Selezionare Memoria nel pannello centrale.
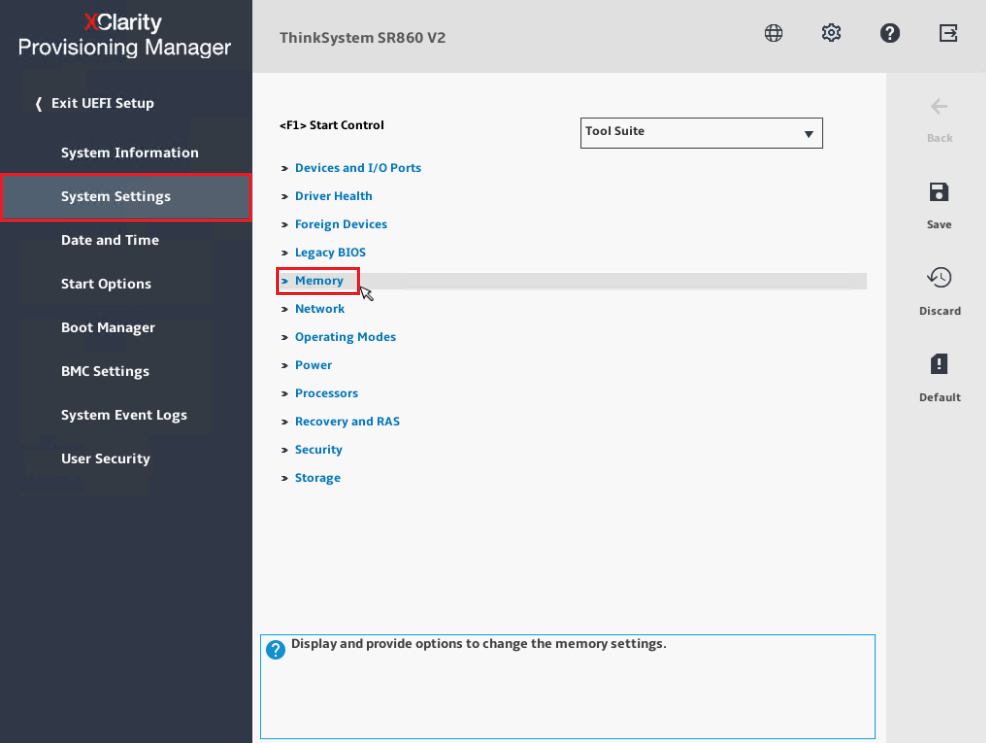
- Scorrere fino in fondo e selezionare Configurazione del Mirror.
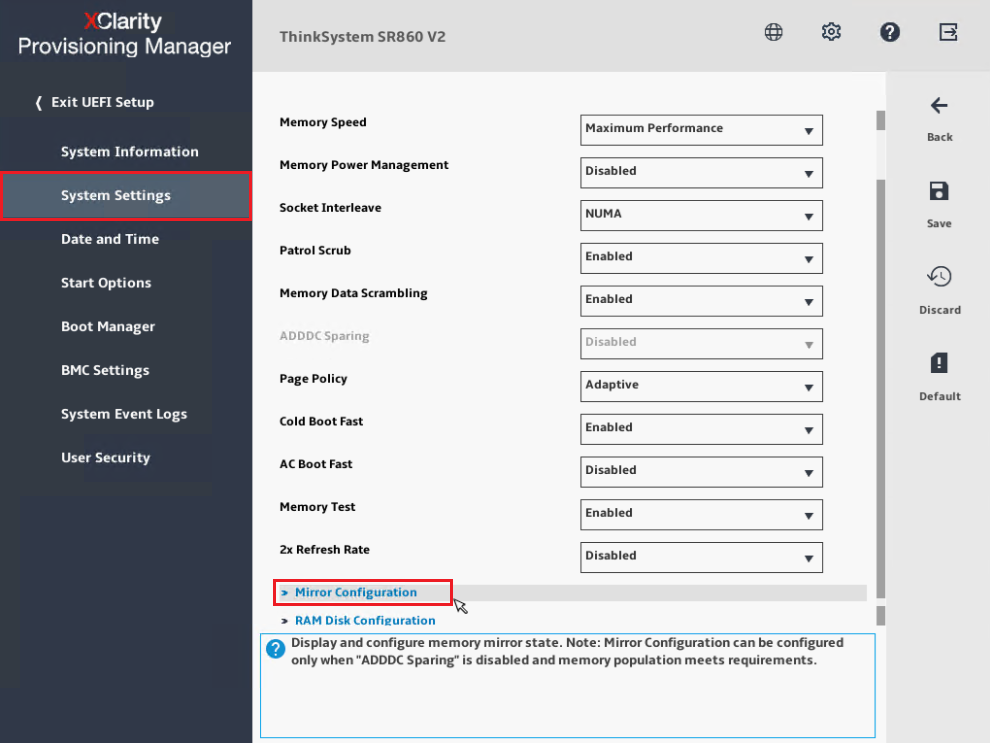
- Impostare Modalità di Mirror su Parziale e abilitare Mirror sotto 4 GB per garantire che il mirroring della memoria includa intervalli di indirizzi bassi.
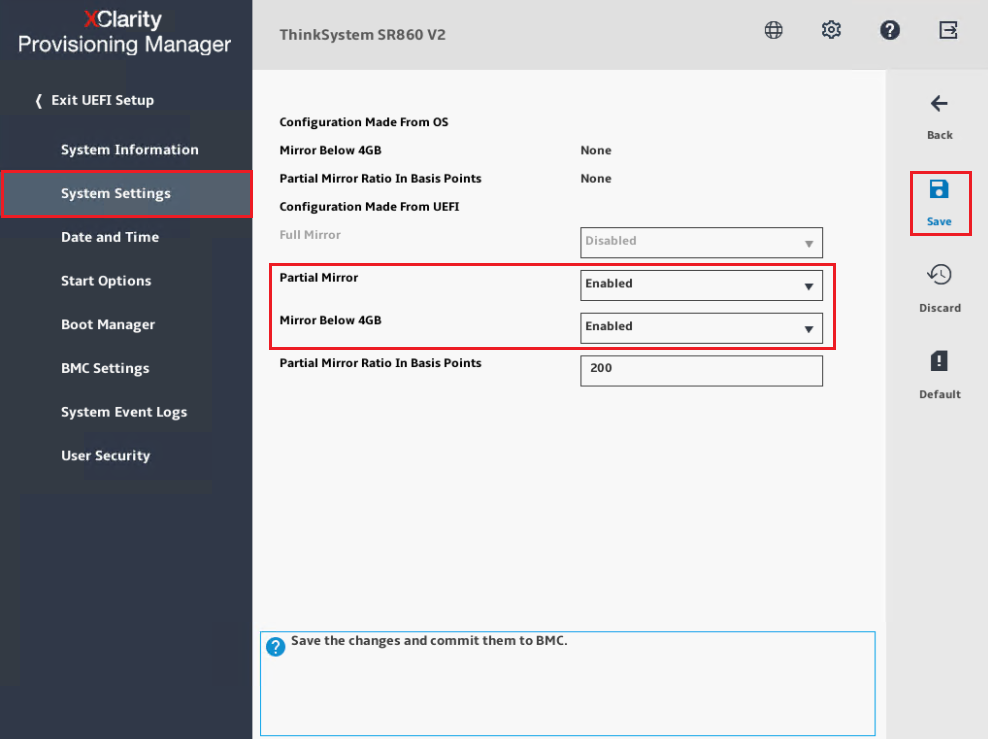
Nota: Mirror sotto 4GB è condiviso con la configurazione MM Base per la quale l'impostazione predefinita è 3 GB. In questo esempio, abbiamo abilitato il Mirror sotto 4 GB.
- Salvare la configurazione ed uscire dal menu di configurazione UEFI.
- Le informazioni sulla memoria del mirror della memoria sono mostrate sulla schermata di avvio del sistema. La capacità di memoria utilizzabile è ridotta in base alla configurazione impostata nell'UEFI. La figura sottostante mostra la modalità di memoria indipendente sul lato sinistro e la modalità di Mirroring dell'Intervallo di Indirizzi sul lato destro dove 1536G di memoria è ridotto a una capacità utilizzabile di 1461GB = 1536(Totale)-36(CPU1)-36(CPU2)-3(Config MM).
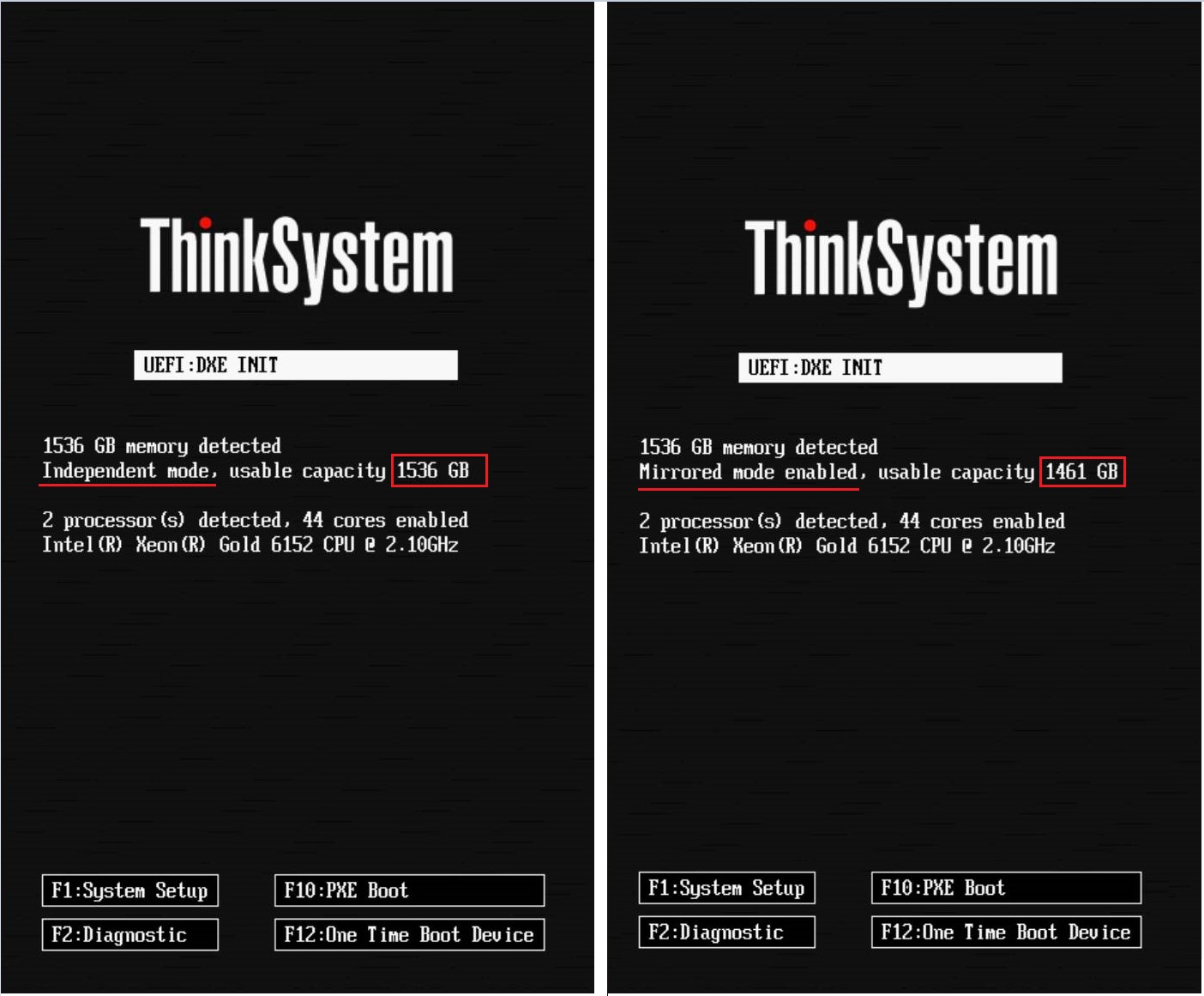
- Nota:
- Linux: Per dettagli su come abilitare e configurare il mirroring parziale della memoria dell'intervallo di indirizzi su Linux, vedere Mirroring Parziale della Memoria dell'Intervallo di Indirizzi su Linux.
- VMware: Per dettagli su come configurare la Memoria Affidabile su base per macchina virtuale (2146595) su VMware, vedere https://kb.vmware.com/s/article/2146595.
- Dopo che il Mirroring Parziale della Memoria è impostato nell'UEFI, si può utilizzare “esxcli hardware memory get” per verificare che la Memoria Affidabile sia utilizzata e sia superiore a ‘0’ Byte.
Fare riferimento all'esempio seguente:Prima di attivare il mirroring parziale della memoria dell'intervallo di indirizzi: [root@h2:~] esxcli hardware memory get Memoria Fisica: 549657530368 Byte Memoria Affidabile: 0 Byte Numero di Nodi NUMA: 2
Dopo aver attivato il mirroring parziale della memoria dell'intervallo di indirizzi: [root@h2:~] esxcli hardware memory get Memoria Fisica: 480938061824 Byte Memoria Affidabile: 68619579392 Byte Numero di Nodi NUMA: 2
Informazioni Aggiuntive
Funzionalità RAS supportate dal Sistema Operativo*
Un insieme di tabelle elencate di seguito mostra quando i fornitori di sistemi operativi hanno adottato per la prima volta singole funzionalità RAS che possono essere utilizzate per migliorare la stabilità del sistema e la resilienza contro gli errori hardware.
* Le tabelle di seguito elencano tutti i principali fornitori di sistemi operativi.
| Funzionalità RAS supportate su Windows Server | WS2016 | WS2019 | WS2022 | Tutte le Versioni Future |
|---|---|---|---|---|
| Recupero MCA2.0 - Percorso di Esecuzione | X | X | X | X |
| Recupero MCA2.0 - Percorso Non di Esecuzione | X | X | X | X |
| Recupero basato su Macchina Locale (LMCE) - Esecuzione | X | X | X | |
| Mirroring dell'Intervallo/Parziale | X | X |
| Funzionalità RAS supportate su VMware ESXi | 5 GA | 5.5 | 6 GA | 6.5-6.7 (tutte) | 7.0 (tutte) | Tutte le Versioni Future |
|---|---|---|---|---|---|---|
| Recupero MCA2.0 - Percorso di Esecuzione | X | X | X | X | X | X |
| Recupero MCA2.0 - Percorso Non di Esecuzione | X | X | X | X | X | X |
| Recupero basato su Macchina Locale (LMCE) - Esecuzione | X | X | X | |||
| Mirroring dell'Intervallo/Parziale | X | X | X | X | X |
| Funzionalità RAS supportate su RHEL | 7.2 | 7.3 | 7.4 (tutte) | 8.x (tutte) | 9.x (tutte) | Tutte le Versioni Future |
|---|---|---|---|---|---|---|
| Recupero MCA2.0 - Percorso di Esecuzione | X | X | X | X | X | X |
| Recupero MCA2.0 - Percorso Non di Esecuzione | X | X | X | X | X | X |
| Recupero basato su Macchina Locale (LMCE) - Esecuzione | X | X | X | X | X | |
| Mirroring dell'Intervallo/Parziale | X | X | X | X |
| Funzionalità RAS supportate su SUSE | 11.04 | 12 GA | 12 SP3 | 12 SP4 (tutte) | 15 (tutte) | Tutte le Versioni Future |
|---|---|---|---|---|---|---|
| Recupero MCA2.0 - Percorso di Esecuzione | X | X | X | X | X | X |
| Recupero MCA2.0 - Percorso Non di Esecuzione | X | X | X | X | X | X |
| Recupero basato su Macchina Locale (LMCE) - Esecuzione | X | X | X | X | ||
| Mirroring dell'Intervallo/Parziale | X | X | X |
| Funzionalità RAS supportate su Ubuntu | 14.04 | 16.04 | 18.04 (tutte) | 20.04 (tutte) | 21.04 (tutte) | Tutte le Versioni Future |
|---|---|---|---|---|---|---|
| Recupero MCA2.0 - Percorso di Esecuzione | X | X | X | X | X | X |
| Recupero MCA2.0 - Percorso Non di Esecuzione | X | X | X | X | X | X |
| Recupero basato su Macchina Locale (LMCE) - Esecuzione | X | X | X | X | X | |
| Mirroring dell'Intervallo/Parziale | X | X | X | X | X |
Recupero MCA
I nuovi processori della famiglia Intel Xeon Scalable supportano il recupero da alcuni errori di memoria basati sul meccanismo di recupero dell'architettura di controllo della macchina (MCA). Ciò richiede che il sistema operativo dichiari una pagina di memoria "contaminata", termini i processi associati alla pagina e eviti di utilizzare la pagina in futuro. Il meccanismo MCA viene utilizzato per rilevare, segnalare e registrare informazioni sugli errori della macchina. Alcuni di questi errori sono correggibili, mentre altri non lo sono. Il meccanismo MCA è progettato per assistere i progettisti di CPU e i debugger di CPU nella diagnosi, isolamento e comprensione dei guasti del processore. È anche destinato ad aiutare gli amministratori di sistema a rilevare guasti transitori e legati all'età, subiti durante il funzionamento a lungo termine del server. La funzionalità di recupero MCA è parte delle capacità di tolleranza ai guasti dei server basati sui processori della famiglia Intel Xeon Scalable, come il portafoglio di server ThinkSystem. Queste capacità consentono ai sistemi di continuare a operare quando viene rilevato un errore non correggibile nel sistema. Se non fosse per queste capacità, il sistema andrebbe in crash e potrebbe richiedere la sostituzione dell'hardware o un riavvio del sistema.
Il recupero MCA consente al sistema operativo di decidere se l'errore può essere recuperato dal sistema operativo senza interrompere il sistema. Se sono soddisfatte le seguenti precondizioni:
- L'errore UCE di memoria è un errore non fatale
- L'indirizzo di errore di memoria non è nello spazio del kernel
- L'applicazione colpita può essere terminata dal sistema operativo host.
La figura sottostante mostra il flusso di gestione degli errori di sistema con un sistema operativo Linux.
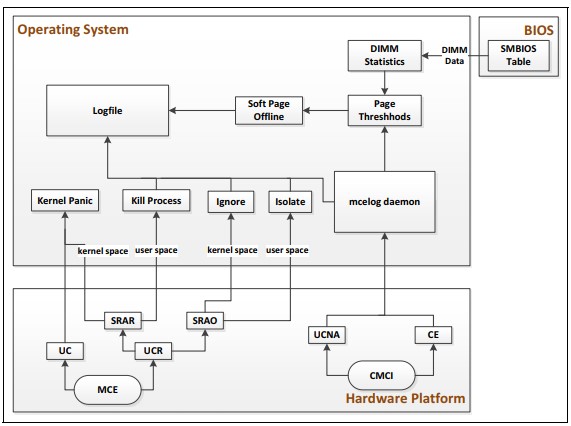
Azione recuperabile dal software richiesta (SRAR): ci sono due tipi di errori rilevati dall'unità cache dati (DCU) e rilevati dall'unità di recupero istruzioni (IFU), nota anche come percorso di esecuzione di recupero MCA.
Azione recuperabile dal software opzionale (SRAO): ci sono due tipi di errori rilevati dal patrol di memoria e rilevati dalla transazione di scrittura esplicita dell'ultimo livello di cache (LLC), nota anche come percorso di non esecuzione di recupero MCA.
Quando si verifica un SRAR/SRAO, il recupero MCA verrà attivato. Se il kernel può eseguire un recupero con successo terminando l'applicazione o la macchina virtuale che ha consumato l'errore di memoria non correggibile, il sistema dovrebbe rimanere online se non vengono rilevati ulteriori errori non correggibili.
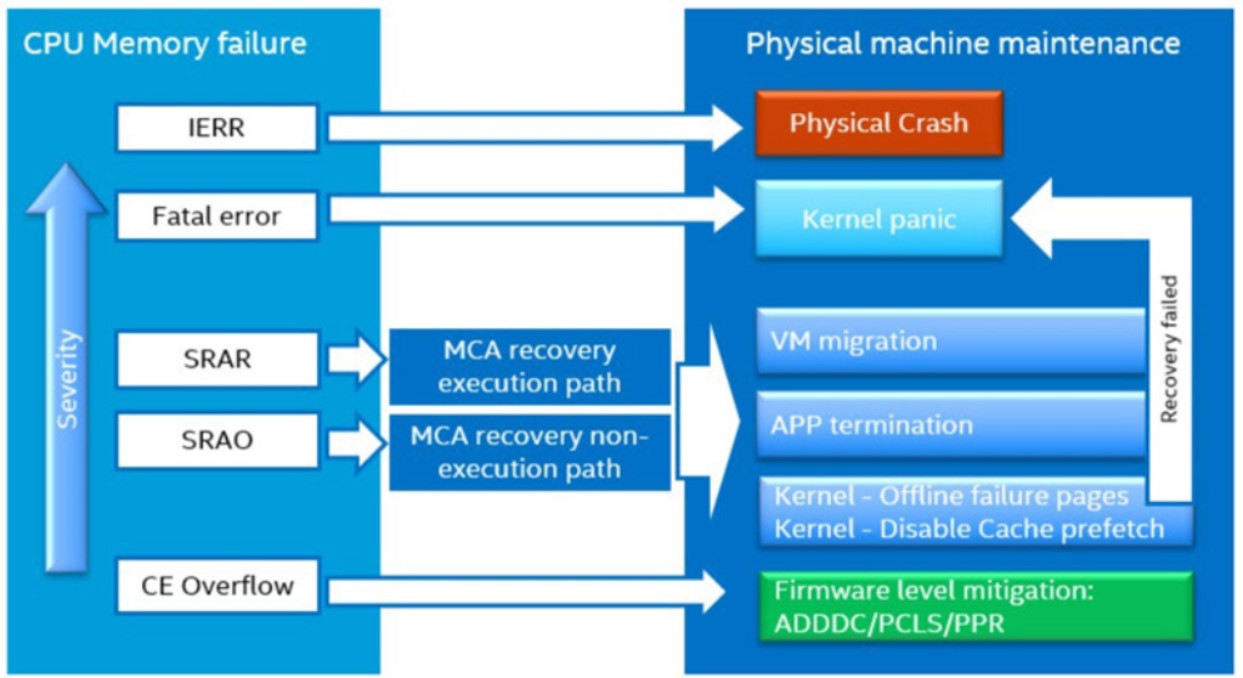
Fonte: Pratica ingegneristica per ridurre il tasso di crash del server da errori di memoria DDR non correggibili (UCE) nei data center cloud hyperscale, vedere URL: Intel® Pratica ingegneristica per ridurre il tasso di crash del server
Mirroring dell'intervallo di indirizzi / Mirroring parziale della memoria
Il mirroring dell'intervallo di indirizzi è una nuova funzionalità RAS di memoria sulla piattaforma Intel Xeon Scalable che consente una maggiore granularità nella selezione di quanta memoria è dedicata alla ridondanza. Le implementazioni di mirroring della memoria (modalità di mirroring completo o modalità di intervallo di indirizzi) sono progettate per consentire il mirroring delle regioni di memoria critiche per aumentare la stabilità della memoria fisica. La memoria mirroring è trasparente per il sistema operativo e le applicazioni. Un'illustrazione sottostante mostra il mirroring dell'intervallo di indirizzi in pratica, dove l'intervallo di indirizzi verde e l'intervallo di indirizzi arancione sono in mirroring.
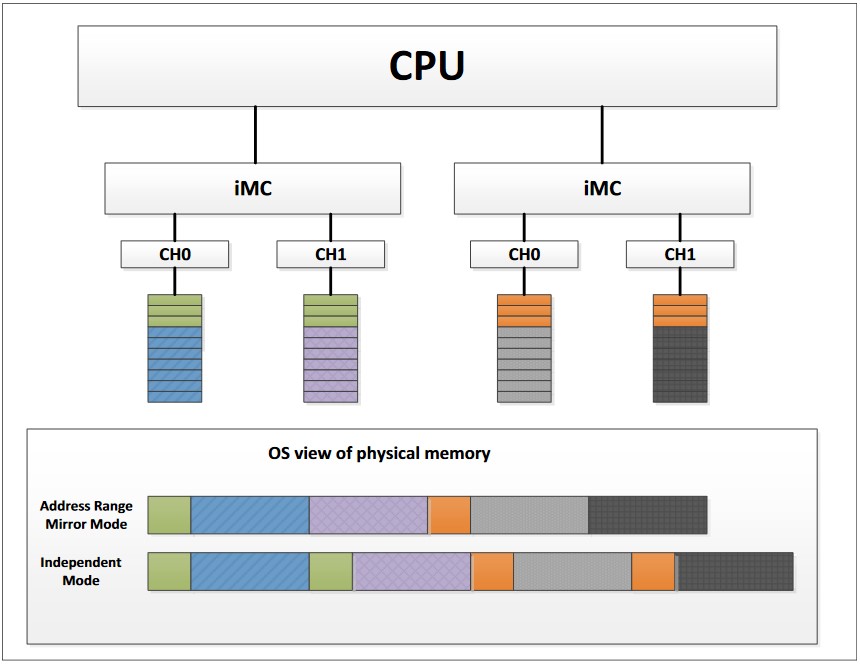
I SKU Intel Xeon Sliver e superiori supportano fino a due intervalli di mirroring in uno socket, un intervallo di mirroring per controller di memoria integrato (iMC). L'intervallo è definito dal valore programmato nel registro del decodificatore di indirizzi di destinazione 0 (TAD0) per il server. Il TAD0 definisce la dimensione degli intervalli di mirroring primario e secondario. L'intervallo di mirroring secondario è riservato per la ridondanza e non viene riportato nella dimensione totale della memoria. Per abilitare il mirroring dell'intervallo di indirizzi, c'è un bit del registro di controllo e stato (CSR) che abilita l'uso del TAD0 per il mirroring.
Il mirroring dell'intervallo di indirizzi offre i seguenti vantaggi:
- Fornisce ulteriore granularità al mirroring della memoria consentendo al firmware o al sistema operativo di determinare un intervallo di indirizzi di memoria da mirroring, lasciando il resto della memoria nello socket in modalità non mirroring.
- Riduce la quantità di memoria riservata per la ridondanza.
- Migliora l'alta disponibilità, evitando errori non correggibili nella memoria del kernel del sistema operativo allocando tutta la memoria del kernel dalla memoria mirroring.
Il mirroring dell'intervallo di indirizzi ha i seguenti requisiti per il sistema operativo e il firmware:
- La modalità di avvio del sistema deve essere impostata su 'UEFI Boot'.
- Richiede supporto del sistema operativo per utilizzare appieno il mirroring dell'intervallo di indirizzi.
- Il sistema operativo deve essere a conoscenza della regione di mirroring.
- Dipendenza dal firmware di sistema per configurare il mirroring dell'intervallo di indirizzi:
- Utilizzando la configurazione UEFI per abilitare il mirroring dell'intervallo di indirizzi con dimensione di mirroring fissa. ThinkSystems spediti con Gen 1, Gen 2 e Gen 3 Intel processori Xeon supportano la configurazione della modalità di mirroring tramite la pagina di configurazione UEFI come descritto in precedenza.
- Utilizzando comandi di configurazione del sistema operativo come “efibootmgr e kernelcore=mirror” per configurare il mirroring dell'intervallo di indirizzi con dimensioni di mirroring diverse tramite l'interfaccia firmware-sistema operativo. ThinkSystems spediti con Gen 1, Gen 2 e Gen 3 Intel processori Xeon hanno supporto di base e c'è un piano per avere supporto completo in una futura generazione di piattaforme che consentirà al sistema operativo di richiedere una percentuale di memoria da mirroring in base alle proprie esigenze uniche.

