Las mejores prácticas de Lenovo en respuesta al manejo de errores de memoria irreparables Intel® en los procesadores Xeon® Scalable de Gen 3, SKU de Gen 1, Gen 2 o "H".
Las mejores prácticas de Lenovo en respuesta al manejo de errores de memoria irreparables Intel® en los procesadores Xeon® Scalable de Gen 3, SKU de Gen 1, Gen 2 o "H".
Las mejores prácticas de Lenovo en respuesta al manejo de errores de memoria irreparables Intel® en los procesadores Xeon® Scalable de Gen 3, SKU de Gen 1, Gen 2 o "H".
Descripción
Lenovo ha sido #1 en fiabilidad durante 7 años y desea informar a sus clientes sobre las reducciones inherentes en todos los sistemas de la industria que utilizan ciertas generaciones de Intel® procesadores, que generacionalmente redujeron las capacidades de verificación y corrección de errores disponibles para los proveedores de sistemas OEM. Una combinación de errores de memoria DDR y cambios arquitectónicos presentes en la lógica de manejo de errores de memoria correctivos, en procesadores Xeon® Scalable de Gen 1 (codenombre "Skylake"), procesadores Xeon® Scalable de Gen 2 (codenombre "Cascade Lake") y procesadores Xeon® Scalable de Gen 3 (codenombre "Cooper Lake-6") puede resultar en una tasa más alta de errores de memoria no corregibles en tiempo de ejecución (UCE) en comparación con generaciones anteriores de hardware. Esto se debe a los cambios implementados en la Corrección de Datos de Dispositivo Único (SDDC). SDDC es una característica fundamental de Intel RAS (Fiabilidad, Disponibilidad, Mantenibilidad) disponible en todas las plataformas. Como resultado de estos cambios arquitectónicos y errores de memoria DIMM, hay una diferencia en qué errores serán corregidos entre la generación anterior de procesadores y la generación de la familia de procesadores Xeon® Scalable. Para más información de Intel® consulte ¿Cómo mejorar el manejo de memoria con procesadores Xeon® Scalable de 1ª, 2ª o 3ª generación Intel®?. Este artículo se centrará en estrategias clave para mitigar errores DDR no corregibles que a veces resultan en la terminación de aplicaciones o caídas de servidores.
El problema puede identificarse observando eventos de error de memoria no corregible o eventos de error de verificación de máquina reportados por Lenovo ThinkSystem o productos ThinkAgile:
FQXSFMA0002M : Se ha detectado un error de memoria no corregible en DIMM [arg1] en la dirección [arg2]. [arg3] FQXSFPU0062F : Ocurrió un error no corregible del sistema en el procesador [arg1] núcleo [arg2] banco MC [arg3] con estado MC [arg4], dirección MC [arg5] y misc MC [arg6]. FQXSFPU0027N : Se ha producido un error recuperable no corregido en el sistema en el procesador [arg1] núcleo [arg2] banco MC [arg3] con estado MC [arg4], dirección MC [arg5] y misc MC [arg6].
(donde XCC = Lenovo Controlador XClarity)
Cada línea a continuación se expandirá con información adicional al hacer clic en la flecha en el lado derecho del título
Sistemas Aplicables
El sistema puede ser cualquiera de los siguientes servidores Lenovo: 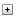
Mejores Prácticas
El firmware de ThinkSystem soporta características RAS ofrecidas por el procesador Intel® Scalable que pueden reducir significativamente la frecuencia de errores DDR no corregibles. Por lo tanto, los administradores y operadores de sistemas deben aprovechar las características RAS soportadas por los procesadores Xeon® Scalable de Gen1/Gen2/Gen3 Intel® y planificar pruebas de memoria rutinarias en el objetivo disponibles dentro de LXPM. Las mejores prácticas descritas en este artículo deberían ser aplicables a futuras generaciones de CPU que soportarán memoria más allá de la generación DDR4 ofrecida con los procesadores Xeon® Scalable de Gen 3 (codenombre "Cooper Lake-6").
Mantener la Actualización del Código
Actualice los servidores de producción ThinkSystem a la pila de firmware lanzada en el primer trimestre de 2021 o superior, lo que asegurará que se hayan aplicado todas las correcciones de firmware conocidas de Intel y Lenovo. Esto se puede hacer navegando a la URL del Portal de Soporte de Lenovo: https://support.lenovo.com y seleccionando el Grupo de Productos apropiado, tipo de Sistema, nombre del Producto, tipo de máquina del Producto y sistema operativo.
Planificar la Selección de Memoria en el Objetivo
Planifique ejecutar pruebas avanzadas de memoria LXPM al menos cada 6 meses y antes de la implementación de un nuevo sistema o mantenimiento del sistema, consulte la URL: HT511056 - La prueba avanzada de memoria LXPM reduce los errores DIMM. Los siguientes pasos deben ser utilizados al considerar esta opción.
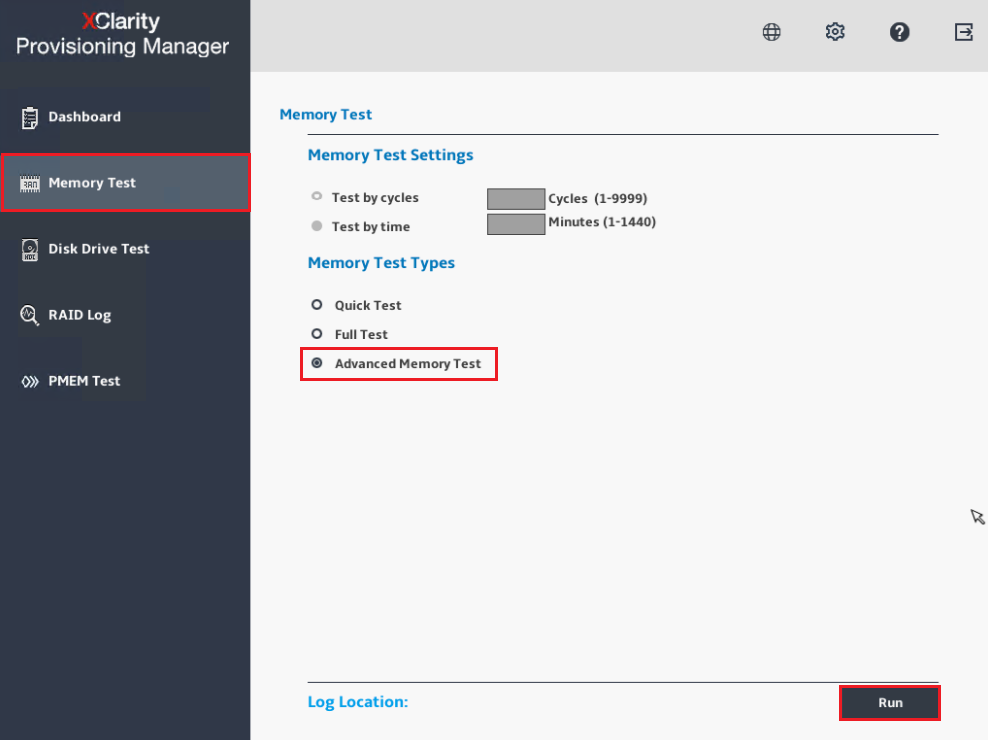
- Mantenga el firmware del sistema (UEFI y BMC/XCC) actualizado: para obtener los mejores resultados, asegúrese de que el sistema objetivo esté ejecutando el firmware más reciente o la pila de firmware lanzada después del primer trimestre de 2021.
- Verifique Información del sistema durante POST o seleccione Resumen del sistema para verificar la información del firmware del sistema:
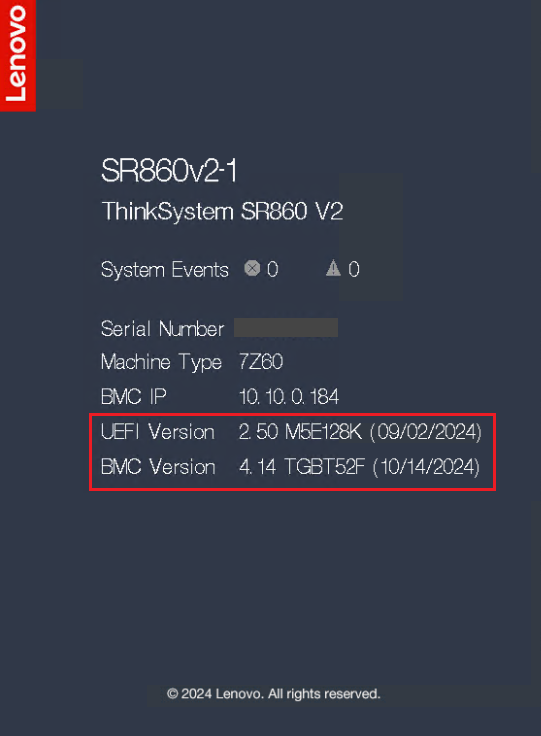
- Verifique Información del sistema durante POST o seleccione Resumen del sistema para verificar la información del firmware del sistema:
- Al utilizar el método de interfaz de línea de comandos (CLI), consulte los comandos a continuación:
Para habilitar el AMT, ejecute:
OneCli.exe config set Memory.MemoryTest Enable --imm xcc_user_id:xcc_password@xcc_external_ip OneCli.exe config set Memory.AdvMemTestOptions 0xF0000 --override --imm xcc_user_id:xcc_password@xcc_external_ip
Para deshabilitar el AMT, ejecute:
OneCli.exe config set Memory.MemoryTest Automatic --imm xcc_user_id:xcc_password@xcc_external_ip OneCli.exe config set Memory.AdvMemTestOptions 0 --override --imm xcc_user_id:xcc_password@xcc_external_ip
- Al utilizar la interfaz gráfica de usuario (GUI), encienda el servidor y presione F1 para ingresar al menú de configuración UEFI, XClarity Provisioning Manager.
- Seleccione la opción Diagnósticos del menú lateral izquierdo.
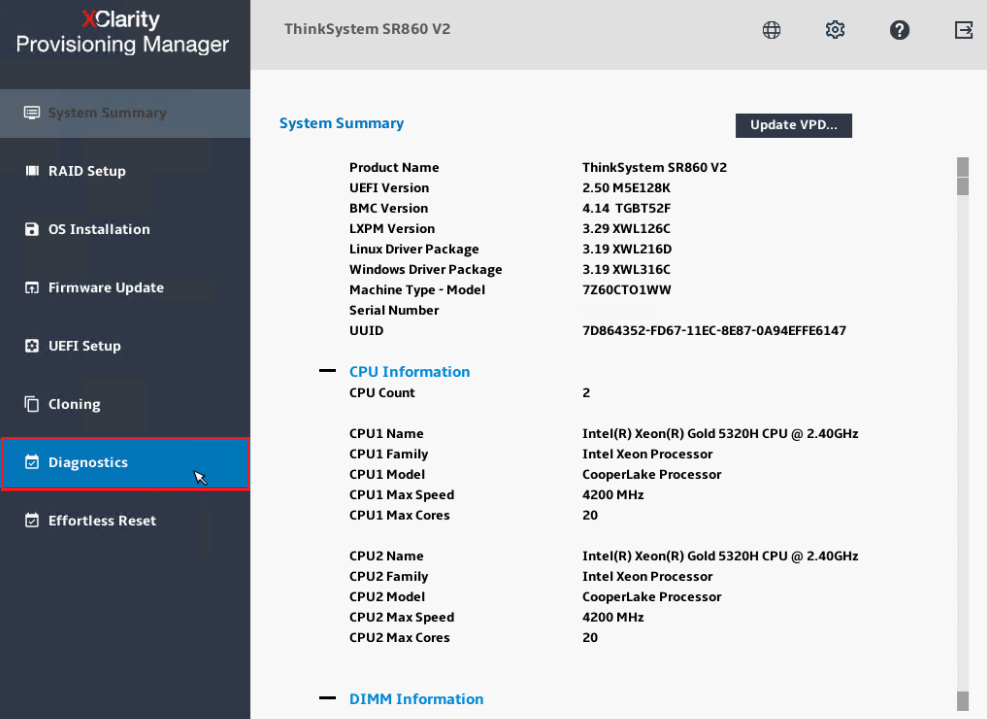
- Seleccione Ejecutar Diagnósticos desde la pantalla de Diagnósticos.
_20250115070109778.png)
- Seleccione Prueba de Memoria desde el Panel de Control.
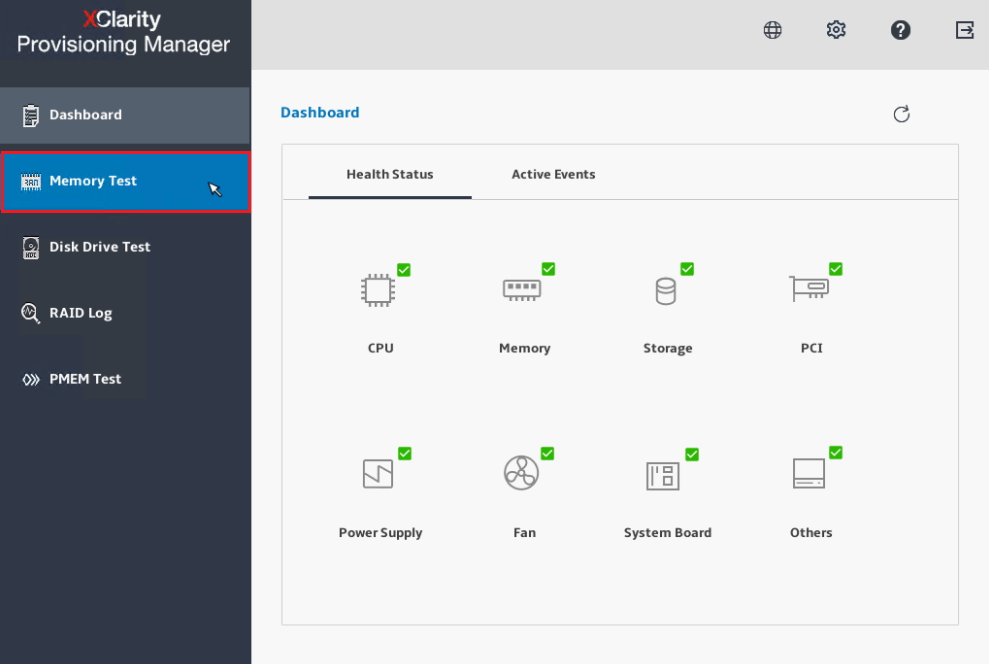
- Seleccione Prueba Avanzada de Memoria desde el menú de Prueba de Memoria.
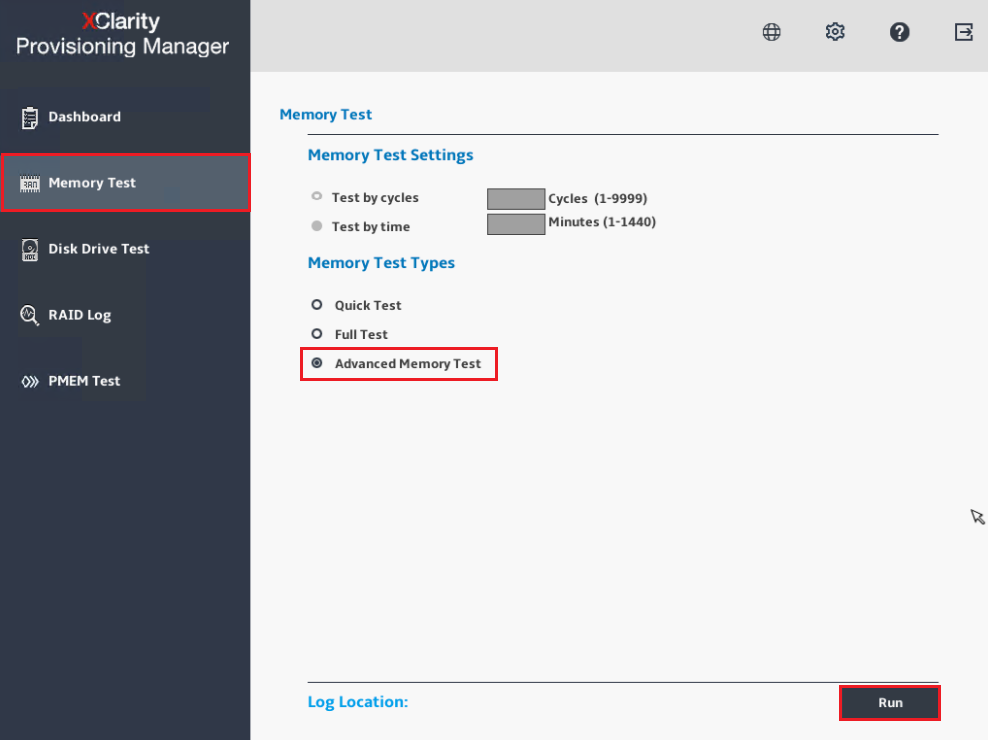

- Después de seleccionar la Prueba Avanzada de Memoria (AMT), el sistema se reiniciará y la prueba de memoria se ejecutará durante el POST UEFI. Esta prueba es muy similar a la prueba de nivel de fabricación y no se puede deshabilitar hasta que se complete un ciclo completo de prueba. Reiniciar el sistema en medio de la operación de prueba reiniciará la prueba de memoria desde el principio, a menos que se retire la batería CMOS. El sistema volverá a la Página de Diagnósticos y proporcionará una interfaz para guardar los registros del sistema cuando esté en la Configuración Gráfica del Sistema.
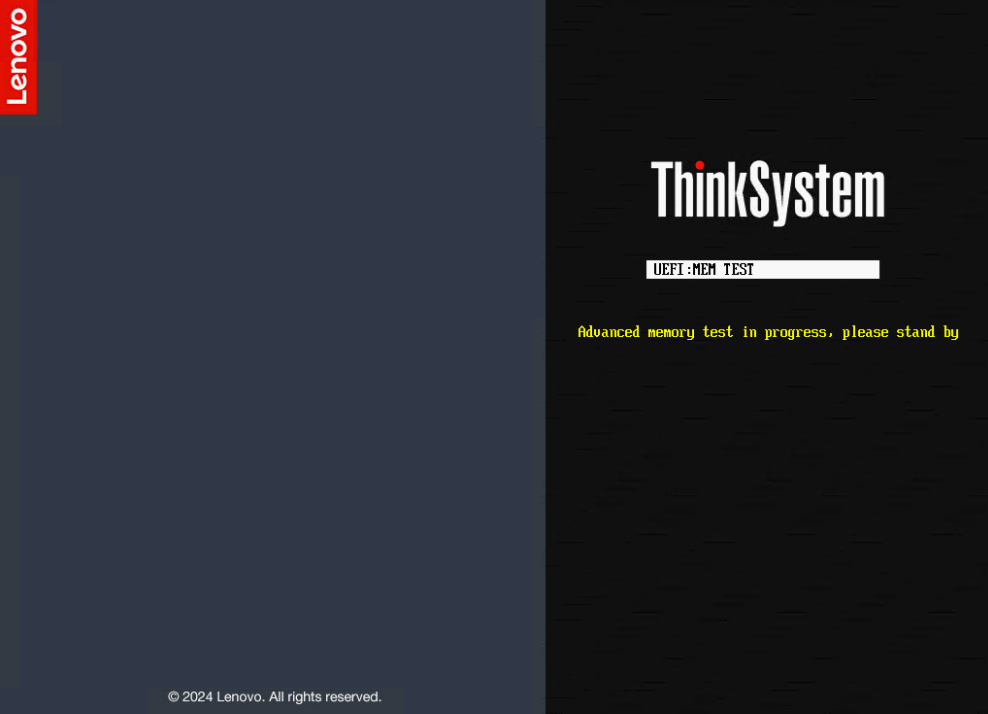
- El tiempo requerido para que la prueba se complete varía según el sistema. Después de que la prueba se complete, el sistema volverá a la página de prueba de memoria en LXPM con un aviso para insertar una USB unidad en el sistema para guardar el archivo de registro. Inserte una USB unidad en el sistema y haga clic en Reintentar para continuar.
- Si un usuario desea omitir la opción de guardar el registro de prueba, entonces la configuración del Sistema F1 debe configurarse para ejecutarse en Modo Texto.
Comando Redfish para habilitar/deshabilitar AMT
{ "Attributes": { "Memory_MemoryTest": "Enabled", "Memory_AdvMemTestOptions": 983040 } }Nota: Para más detalles, consulte Prueba Avanzada de Memoria en Servidores Basados en Xeon ThinkSystem.
Habilitar Recuperación de Comprobación de Máquina (MCA) y Recuperación de Comprobación de Máquina Local (LMCE)
La recuperación MCA permite que el sistema operativo decida si el error puede ser recuperado por el sistema operativo sin apagar el sistema. Para más información sobre esta característica RAS, consulte la sección de detalles. Para obtener información más detallada sobre la recuperación MCA, consulte la sección de Información Adicional.
Los siguientes pasos deben ser utilizados al considerar esta opción.
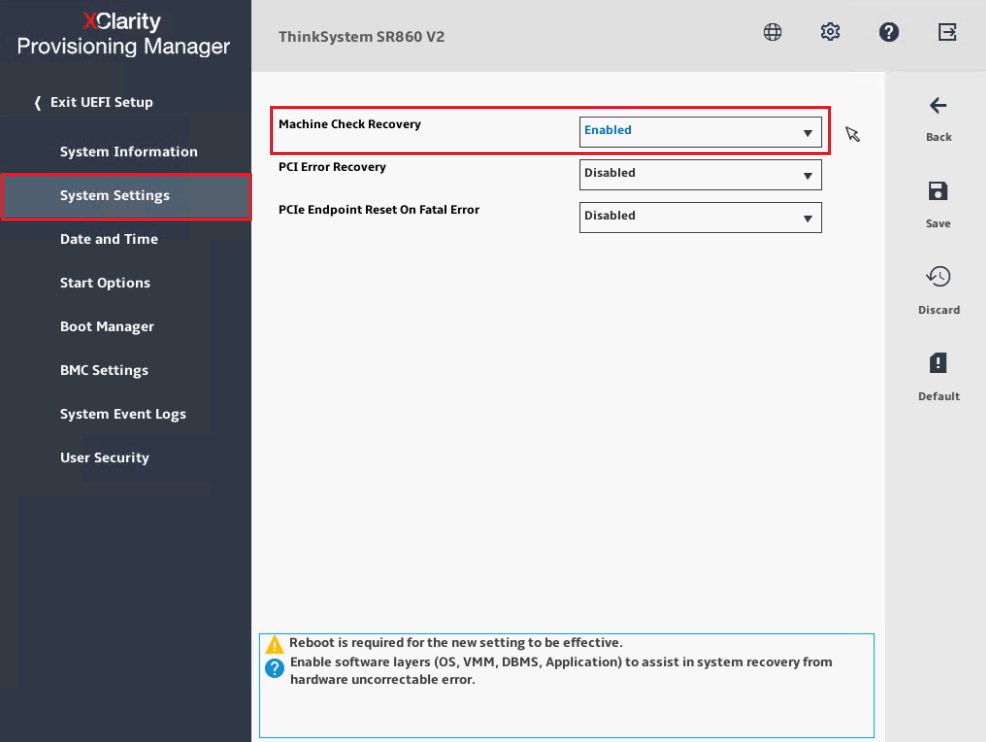
- Al utilizar el método CLI, seleccione “AdvancedRAS.MachineCheckRecovery=Enable”. Esta característica está habilitada por defecto en la configuración UEFI.
- Al utilizar el método GUI:
- Encienda el servidor.
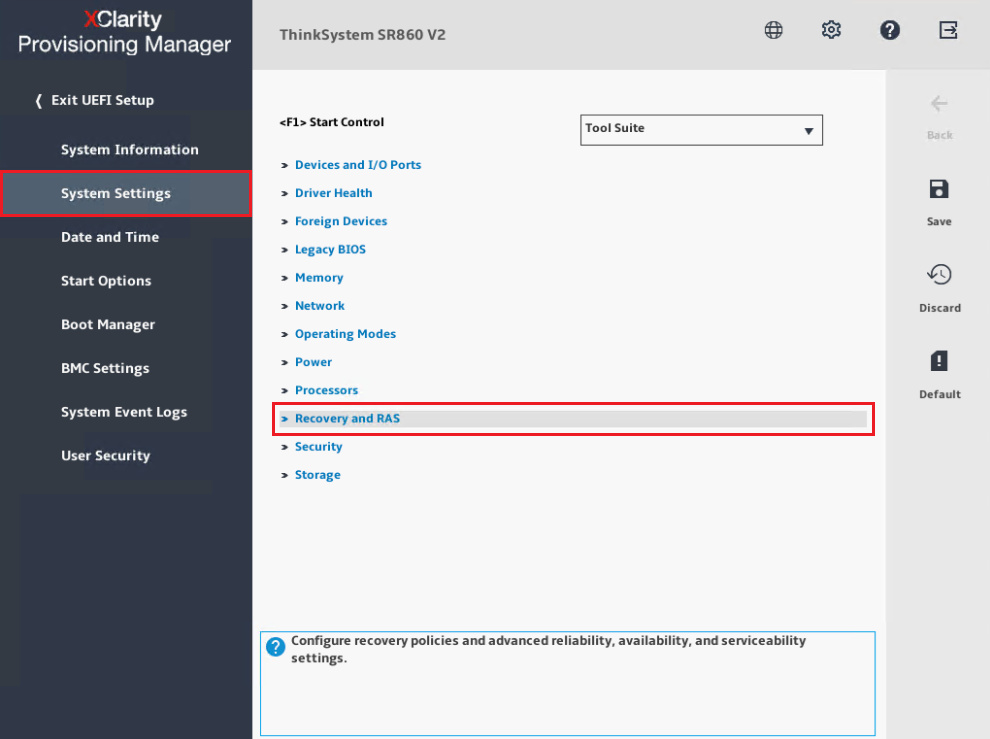
- Presione F1 para ingresar a la Configuración del Sistema, LXPM.
- Desde el menú de navegación izquierdo, seleccione Configuración del Sistema→ Recuperación y RAS como se muestra a continuación.
- Seleccione RAS Avanzado.
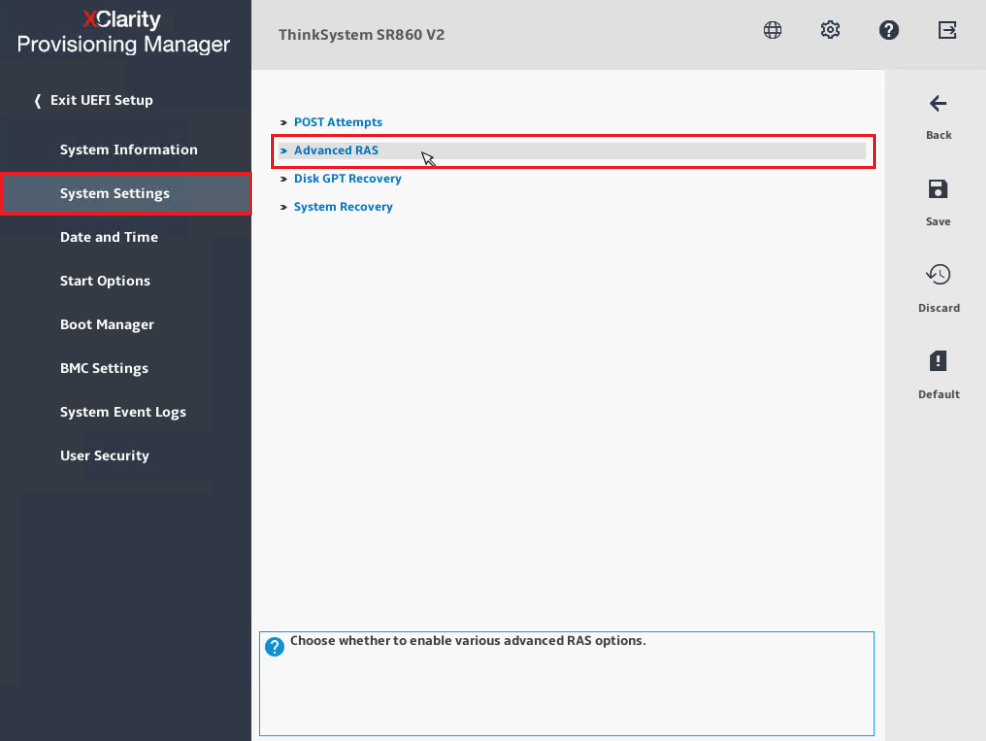
- Habilite Recuperación de Comprobación de Máquina.
Nota: La recuperación MCA y la Recuperación de Comprobación de Máquina Local (LMCE) dependen del soporte del sistema operativo, por lo que consulte con su proveedor de sistema operativo sobre la capacidad de MCA y LMCE, ya que cada proveedor de sistema operativo adopta características RAS utilizando sus propios ciclos de lanzamiento. El firmware de la plataforma basado en Lenovo habilita la recuperación basada en LMCE por defecto, pero esta configuración no se expone al Espacio de Usuario en la Configuración UEFI. Los beneficios de LMCE sobre MCE se discuten en el siguiente documento: Manejo de Excepciones de Comprobación de Máquina Local en Linux.
Windows: Para una descripción detallada de cómo Windows utiliza características RAS, consulte la Windows Guía de diseño de Arquitectura de Errores de Hardware (WHEA). Consulte la sección “Información Adicional” para la lista de características RAS soportadas por el sistema operativo.
VMware: La recuperación de Comprobación de Máquina es soportada por el núcleo en la versión ESXi 5 y superiores. Consulte la sección “Información Adicional” para la lista de características RAS soportadas por el sistema operativo.
Además, el usuario debe aprovechar la Recuperación basada en Comprobación de Máquina Local (LMCE) que está habilitada por defecto en la versión ESXi 7.0, consulte Lenovo ThinkSystem Servidores con soporte para Módulo de Memoria Persistente Optane™ DC de Intel®
Para el Lenovo ThinkSystem SR850P y SR850, debido a una limitación de hardware conocida, es necesario habilitar la bandera de arranque del núcleo “useLMCE” para soportar la recuperación de errores de comprobación de máquina local con ESXi 6.7 U2 y versiones superiores.
- Para habilitar la recuperación local de MCE en un sistema ESXi 6.7 U2:
En la consola de ESXi, ejecute estos dos comandos esxcli para establecer la opción de arranque del núcleo, use LMCE a TRUE, luego reinicie el sistema para que los cambios surtan efecto.esxcli system settings kernel set -s useLMCE -v TRUE /sbin/reboot
Después de un reinicio, verifique que la configuración haya surtido efecto ejecutando este comando:esxcli system settings kernel list -o “useLMCE”
Linux: Consulte la sección “Información Adicional” para la lista de características RAS soportadas por el sistema operativo. Lista de Soporte del Núcleo para recuperación MCA por los principales proveedores de Linux:

Fuente: Práctica de Ingeniería para Reducir la Tasa de Fallos de Servidores por Errores No Corregibles de DDR (UCE) en Centros de Datos en Nubes Hiperescalables, consulte Práctica de Ingeniería para Reducir Fallos de Servidores
Mantener Habilitada la Limpieza de Patrón
Para evitar la acumulación de errores suaves que pueden convertirse en errores no corregibles (UCE), el chipset Intel tiene un motor de limpieza de memoria incorporado. Lee datos de cada ubicación de memoria DDR y corrige errores de bits (si los hay) con un código de corrección de errores (ECC), luego escribe los datos corregidos de nuevo en la misma ubicación. La limpieza de patrón está configurada para un intervalo de 24 horas donde cada dirección se verifica durante este período.
- Al utilizar el método CLI, seleccione “Memory.PatrolScrub=Enable”. Esta característica está habilitada por defecto en la configuración UEFI.
Deshabilitar Arranque Rápido en Frío
Forzar el Entrenamiento de Memoria en cada reinicio deshabilitando el Arranque Rápido en Frío, esto aumentará el tiempo de arranque del sistema durante el POST. El propósito del Arranque Rápido en Frío es omitir el entrenamiento de memoria si no se ha detectado ningún cambio de configuración en los últimos 90 días, lo que mejora el tiempo de arranque del sistema. Deshabilitar el Arranque Rápido en Frío permite el reentrenamiento de la interfaz de memoria, compensando cualquier cambio significativo en las condiciones ambientales.
- Al utilizar el método CLI, seleccione “Memory.ColdBootFast=Disable”.
- Esta característica está habilitada por defecto en la configuración UEFI.
Aprovechar la Reparación de Paquete Post
Esta es una característica liderada por la industria definida por JEDEC para habilitar la Reparación de Paquete Post (PPR) en Tiempo de Arranque para reemplazar una fila, dentro de un DRAM, que se determina que está defectuosa. La intención de la característica es reducir los reemplazos de DIMM en el campo debido a la presencia de celdas defectuosas. Durante el tiempo de ejecución, un DIMM que experimenta fallos corregibles puede ser programado para que se realice una PPR en un ciclo de arranque posterior. El DRAM que experimenta el fallo, dentro del DIMM, tendrá la fila reemplazada internamente por una fila de repuesto, dentro del mismo DRAM. Este proceso de fusión correctiva de PPR es permanente.
Por ejemplo, si su sistema afirmó un PFA en tiempo de ejecución, entonces en el próximo ciclo de reinicio, UEFI intentará una reparación. Esto se indicará con un mensaje de “Auto-Reparación” en el registro de eventos, y después de completarse, el PFA será desactivado.
Establecer el Modo de Operación del Sistema en Rendimiento Máximo
En algunas situaciones, se observó que deshabilitar las políticas de gestión de energía en el UEFI del sistema y en el cliente de vSphere ha resuelto errores intermitentes de 'Bus no corregibles' o reinicios del sistema y errores de memoria.
- Al utilizar el método CLI, seleccione “OperatingModes.ChooseOperatingMode=Maximum Performance".
- Para habilitar el rendimiento máximo utilizando el método CLI, ejecute:
OneCli.exe config set OperatingModes.ChooseOperatingMode "Maximum Performance" --imm xcc_user_id:xcc_password@xcc_external_ip
Para referencia, consulte la optimización del sistema para VMware en servidores x86 y ThinkSystem, consulte la optimización del sistema para VMware en servidores x86 y ThinkSystem
Para referencia, consulte la configuración UEFI recomendada - Lenovo sistemas ThinkAgile HX, consulte la URL: Configuraciones UEFI recomendadas
Habilitar la duplicación de rango de direcciones / Duplicación parcial de memoria
La duplicación de rango de direcciones es una característica RAS disponible en las plataformas de la familia Xeon Scalable Intel que permite un control granular sobre cuánta memoria se asigna para redundancia, consulte la sección de detalles para información adicional. Los siguientes pasos deben ser utilizados al considerar esta opción. Para información más detallada sobre la duplicación de rango de direcciones, consulte la sección de información adicional.
- Al utilizar el método CLI, seleccione “Memory.MirrorMode=Partial”, “Memory.Mirrorbelow4GB=Enable”
- Cuando la duplicación de rango de direcciones está habilitada, el contenido de la memoria se duplicará en el DIMM remoto en la partición. Esto significa que no toda la memoria del sistema estará disponible para el sistema operativo. Por ejemplo, con la duplicación parcial habilitada, UEFI dedicará 36 GB de una cantidad fija de memoria al espejo por procesador físico.
- Siga los pasos a continuación para habilitar el modo de espejo parcial para redundancia de memoria:
- Encienda el servidor.
- Presione la tecla F1 para ingresar a LXPM:
- Seleccione Configuración UEFI en el menú de navegación izquierdo.
- Seleccione Configuraciones del sistema.
- Seleccione Memoria en el panel central.
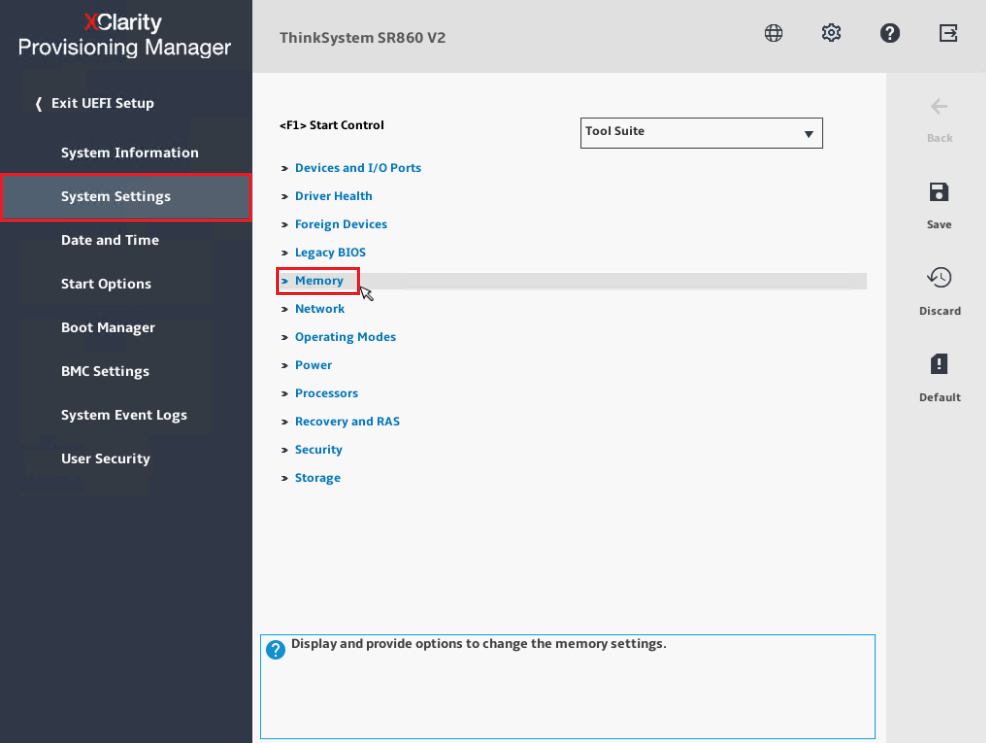
- Desplácese hacia abajo hasta el final y seleccione Configuración de espejo.
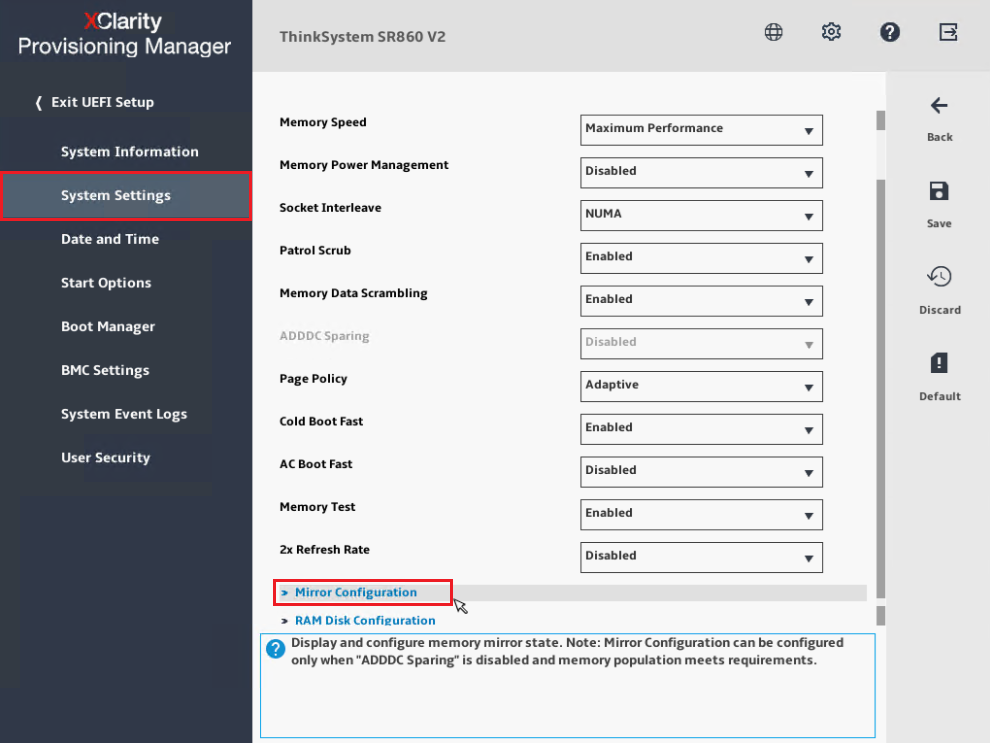
- Establezca Modo de espejo en Parcial y habilite Espejo por debajo de 4 GB para asegurar que la duplicación de memoria incluya rangos de direcciones bajas.
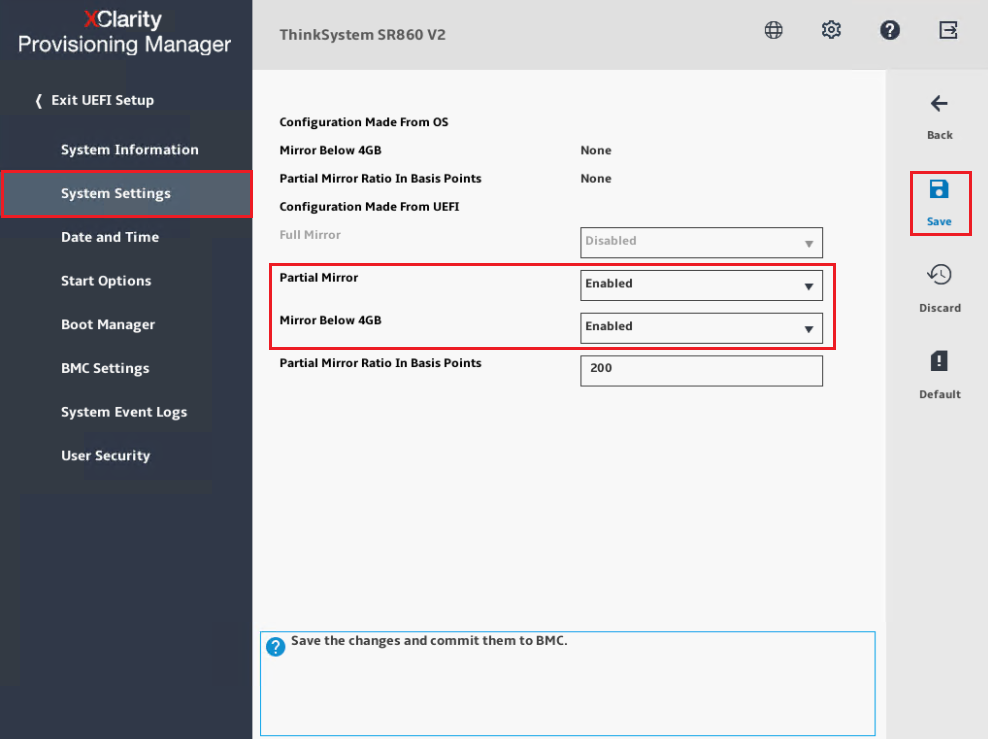
Nota: Espejo por debajo de 4GB se comparte con la configuración base de MM, para la cual la configuración predeterminada es 3 GB. En este ejemplo, habilitamos el espejo por debajo de 4 GB.
- Guarde la configuración y salga del menú de configuración UEFI.
- La información de memoria del espejo de memoria se muestra en la pantalla de arranque del sistema. La capacidad de memoria utilizable se reduce de acuerdo con la configuración que se estableció en UEFI. La figura a continuación muestra el modo independiente de memoria en el lado izquierdo y el modo de duplicación de rango de direcciones en el lado derecho, donde 1536G de memoria se reduce a una capacidad utilizable de 1461GB = 1536(Total)-36(CPU1)-36(CPU2)-3(Config. MM).
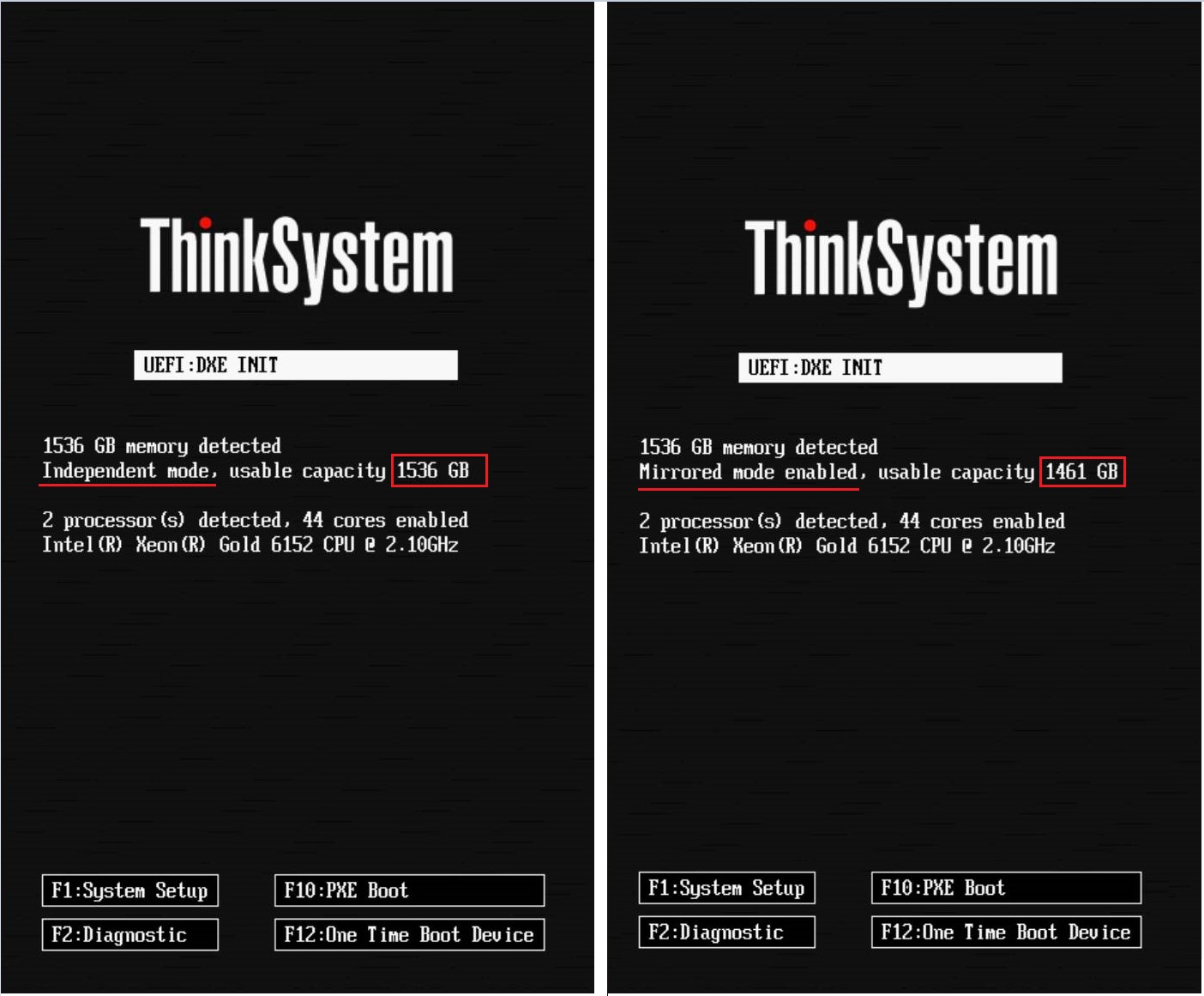
- Nota:
- Linux: Para detalles sobre cómo habilitar y configurar la duplicación parcial de memoria de rango de direcciones en Linux, consulte Duplicación parcial de memoria de rango de direcciones en Linux.
- VMware: Para detalles sobre cómo configurar la memoria confiable en base a cada máquina virtual (2146595) en VMware, consulte https://kb.vmware.com/s/article/2146595.
- Después de que la duplicación parcial de memoria se establezca en UEFI, se puede usar “esxcli hardware memory get” para verificar que se está utilizando memoria confiable y que está por encima de ‘0’ Bytes.
Consulte el ejemplo a continuación:Antes de activar la duplicación parcial de memoria de rango de direcciones: [root@h2:~] esxcli hardware memory get Memoria física: 549657530368 Bytes Memoria confiable: 0 Bytes Conteo de nodos NUMA: 2
Después de activar la duplicación parcial de memoria de rango de direcciones: [root@h2:~] esxcli hardware memory get Memoria física: 480938061824 Bytes Memoria confiable: 68619579392 Bytes Conteo de nodos NUMA: 2
Información adicional
Características RAS soportadas por el sistema operativo*
Un conjunto de tablas que se enumeran a continuación muestra cuándo los proveedores de sistemas operativos han adoptado por primera vez características RAS individuales que se pueden utilizar para mejorar la estabilidad del sistema y la resiliencia contra errores de hardware.
* Las tablas a continuación enumeran todos los principales proveedores de sistemas operativos.
| Características RAS soportadas en el servidor Windows | WS2016 | WS2019 | WS2022 | Todas las versiones futuras |
|---|---|---|---|---|
| Recuperación MCA2.0 - Ruta de ejecución | X | X | X | X |
| Recuperación MCA2.0 - Ruta no de ejecución | X | X | X | X |
| Recuperación basada en máquina local (LMCE) - Ejecución | X | X | X | |
| Duplicación de rango de direcciones/parcial | X | X |
| Características RAS soportadas en VMware ESXi | 5 GA | 5.5 | 6 GA | 6.5-6.7 (todas) | 7.0 (todas) | Todas las versiones futuras |
|---|---|---|---|---|---|---|
| Recuperación MCA2.0 - Ruta de ejecución | X | X | X | X | X | X |
| Recuperación MCA2.0 - Ruta no de ejecución | X | X | X | X | X | X |
| Recuperación basada en máquina local (LMCE) - Ejecución | X | X | X | |||
| Duplicación de rango de direcciones/parcial | X | X | X | X | X |
| Características RAS soportadas en RHEL | 7.2 | 7.3 | 7.4 (todas) | 8.x (todas) | 9.x (todas) | Todas las versiones futuras |
|---|---|---|---|---|---|---|
| Recuperación MCA2.0 - Ruta de ejecución | X | X | X | X | X | X |
| Recuperación MCA2.0 - Ruta no de ejecución | X | X | X | X | X | X |
| Recuperación basada en máquina local (LMCE) - Ejecución | X | X | X | X | X | |
| Duplicación de rango de direcciones/parcial | X | X | X | X |
| Características RAS soportadas en SUSE | 11.04 | 12 GA | 12 SP3 | 12 SP4 (todas) | 15 (todas) | Todas las versiones futuras |
|---|---|---|---|---|---|---|
| Recuperación MCA2.0 - Ruta de ejecución | X | X | X | X | X | X |
| Recuperación MCA2.0 - Ruta no de ejecución | X | X | X | X | X | X |
| Recuperación basada en máquina local (LMCE) - Ejecución | X | X | X | X | ||
| Duplicación de rango de direcciones/parcial | X | X | X |
| Características RAS soportadas en Ubuntu | 14.04 | 16.04 | 18.04 (todas) | 20.04 (todas) | 21.04 (todas) | Todas las versiones futuras |
|---|---|---|---|---|---|---|
| Recuperación MCA2.0 - Ruta de ejecución | X | X | X | X | X | X |
| Recuperación MCA2.0 - Ruta no de ejecución | X | X | X | X | X | X |
| Recuperación basada en máquina local (LMCE) - Ejecución | X | X | X | X | X | |
| Duplicación de rango de direcciones/parcial | X | X | X | X | X |
Recuperación MCA
Los nuevos procesadores de la familia Intel Xeon Scalable admiten la recuperación de algunos errores de memoria basados en el mecanismo de recuperación de la Arquitectura de Comprobación de Máquina (MCA). Esto requiere que el sistema operativo declare una página de memoria como "envenenada", finalice los procesos asociados con la página y evite usar la página en el futuro. El mecanismo MCA se utiliza para detectar, señalar y registrar información sobre fallos de la máquina. Algunos de estos fallos son corregibles, mientras que otros son irreparables. El mecanismo MCA está destinado a ayudar a los diseñadores de CPU y a los depuradores de CPU a diagnosticar, aislar y comprender las fallas del procesador. También está destinado a ayudar a los administradores de sistemas a detectar fallas transitorias y relacionadas con la edad, sufridas durante la operación a largo plazo del servidor. La función de recuperación MCA es parte de las capacidades de tolerancia a fallos de los servidores basados en los procesadores de la familia Intel Xeon Scalable, como la cartera de servidores ThinkSystem. Estas capacidades permiten que los sistemas continúen operando cuando se detecta un error no corregible en el sistema. Si no fuera por estas capacidades, el sistema se bloquearía y podría requerir un reemplazo de hardware o un reinicio del sistema.
La recuperación MCA permite que el sistema operativo decida si el error puede ser recuperado por el sistema operativo sin detener el sistema. Si se cumplen las siguientes precondiciones:
- El UCE de memoria es un error no fatal
- La dirección de falla de memoria no está en el espacio del núcleo
- La aplicación afectada puede ser finalizada por el sistema operativo anfitrión.
La figura a continuación muestra el flujo de manejo de errores del sistema con un sistema operativo Linux.
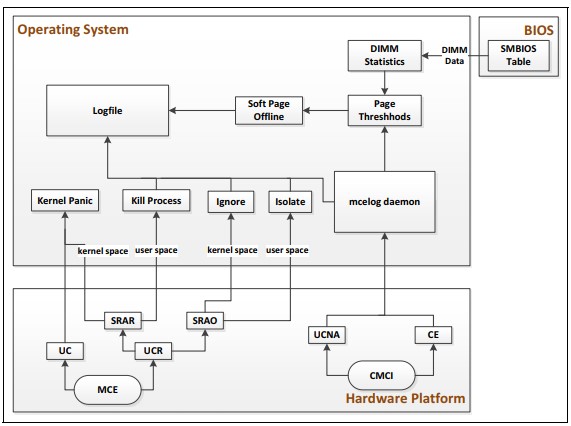
Acción recuperable por software requerida (SRAR): Hay dos tipos de errores detectados por la Unidad de Caché de Datos (DCU) y detectados por la Unidad de Recuperación de Instrucciones (IFU), también conocida como ruta de ejecución de recuperación MCA.
Acción recuperable por software opcional (SRAO): Hay dos tipos de errores detectados por el patrullaje de memoria y detectados por la transacción de escritura explícita de la Caché de Último Nivel (LLC), también conocida como ruta de no ejecución de recuperación MCA.
Cuando ocurre un SRAR/SRAO, se activará la recuperación MCA. Si el núcleo puede realizar una recuperación exitosa al finalizar la aplicación o la Máquina Virtual que consumió el error de memoria no corregible, el sistema debería permanecer en línea si no se detectan errores no corregibles adicionales.
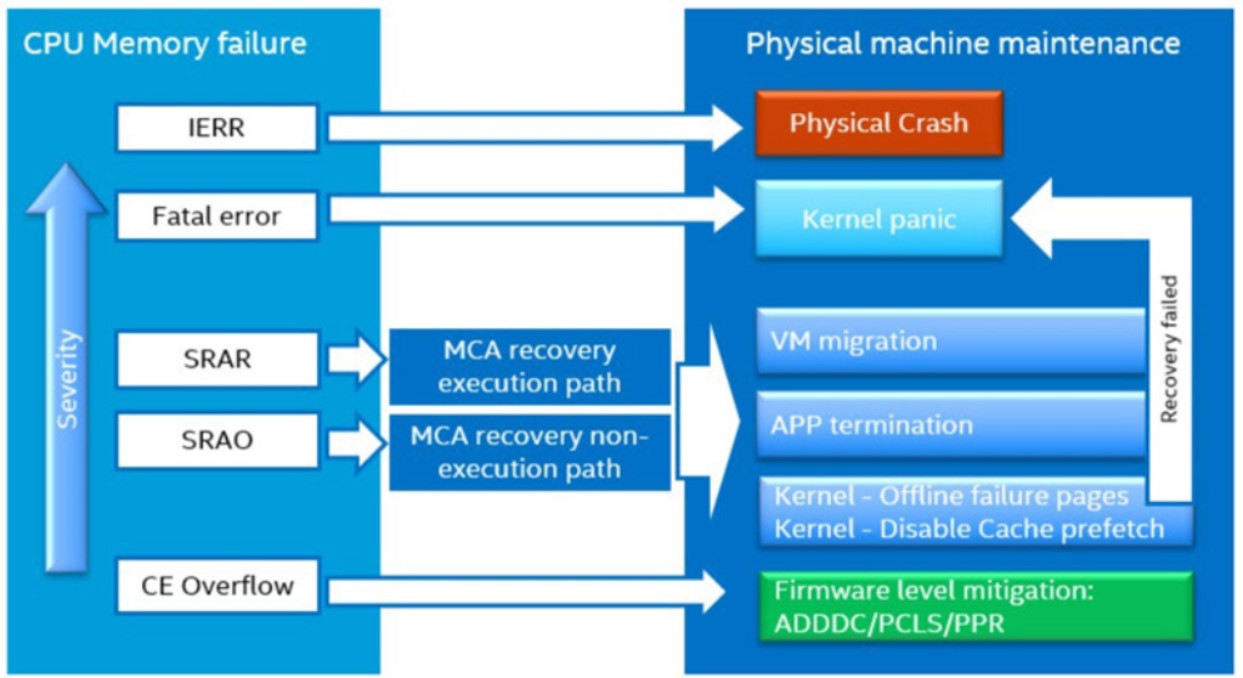
Fuente: Práctica de Ingeniería para Reducir la Tasa de Fallos de Servidores por Errores de Memoria DDR No Corregibles (UCE) en Centros de Datos de Nube Hiperescalables, ver URL: Intel® Práctica de Ingeniería para Reducir la Tasa de Fallos de Servidores
Espejo de Rango de Direcciones / Espejo de Memoria Parcial
El Espejo de Rango de Direcciones es una nueva característica de RAS de memoria en la plataforma Intel Xeon Scalable que permite una mayor granularidad en la selección de cuánta memoria se dedica a la redundancia. Las implementaciones de espejo de memoria (modo de espejo completo o modo de rango de direcciones) están diseñadas para permitir el espejado de regiones críticas de memoria para aumentar la estabilidad de la memoria física. La memoria espejada es transparente para el sistema operativo y las aplicaciones. Una ilustración a continuación muestra el Espejo de Rango de Direcciones en práctica, donde el rango de direcciones verde y el rango de direcciones naranja están en espejo.
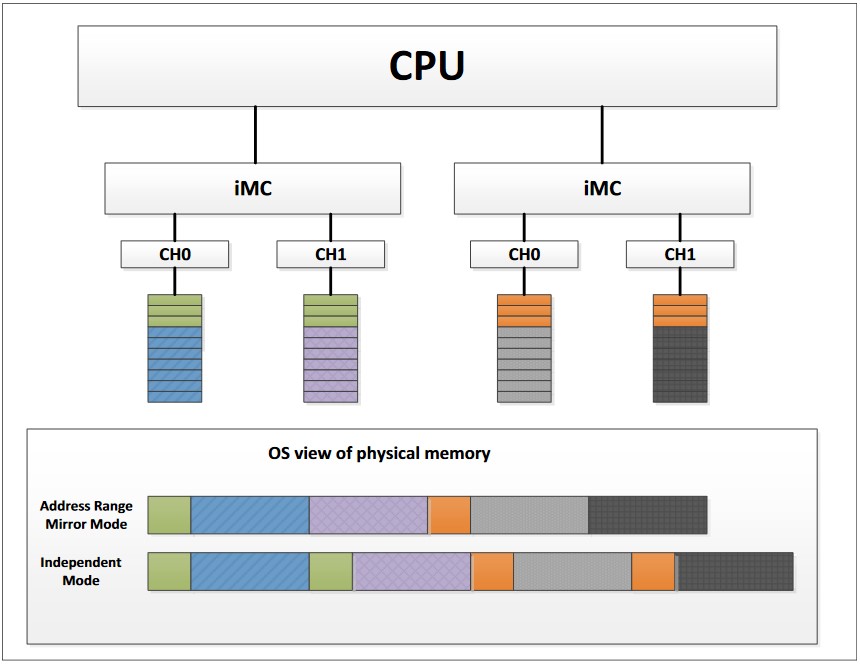
Los SKU de Xeon Sliver Intel y superiores admiten hasta dos rangos de espejo en un socket, un rango de espejo por Controlador de Memoria Integrado (iMC). El rango se define por el valor programado en el registro del Decodificador de Dirección Objetivo 0 (TAD0) para el servidor. El TAD0 define el tamaño de los rangos de espejo primario y secundario. El rango de espejo secundario se reserva para redundancia y no se informa en el tamaño total de la memoria. Para habilitar el Espejo de Rango de Direcciones, hay un bit en el Registro de Control y Estado (CSR) que habilita el uso de TAD0 para el espejado.
El Espejo de Rango de Direcciones ofrece los siguientes beneficios:
- Proporciona una mayor granularidad al espejado de memoria al permitir que el firmware o el sistema operativo determinen un rango de direcciones de memoria que se espejarán, dejando el resto de la memoria en el socket en modo no espejo.
- Reduce la cantidad de memoria reservada para redundancia.
- Mejora la alta disponibilidad, evitando errores no corregibles en la memoria del núcleo del sistema operativo al asignar toda la memoria del núcleo desde la memoria espejada.
El Espejo de Rango de Direcciones tiene los siguientes requisitos para el sistema operativo y firmware:
- El modo de arranque del sistema debe estar configurado como 'Arranque UEFI'.
- Requiere soporte del sistema operativo para utilizar completamente el Espejo de Rango de Direcciones.
- El sistema operativo debe ser consciente de la región espejada.
- Dependencia del firmware del sistema para configurar el Espejo de Rango de Direcciones:
- Usando la configuración UEFI para habilitar el Espejo de Rango de Direcciones con un tamaño de espejo fijo. Los ThinkSystem enviados con Gen 1, Gen 2 y Gen 3 de procesadores Xeon Intel admiten la configuración del modo espejo a través de la Página de Configuración UEFI como se describió anteriormente.
- Usando comandos de configuración del sistema operativo como “efibootmgr y kernelcore=mirror” para configurar el Espejo de Rango de Direcciones con un tamaño de espejo diferente a través de la interfaz firmware-sistema operativo. Los ThinkSystem enviados con Gen 1, Gen 2 y Gen 3 de procesadores Xeon Intel tienen soporte básico y hay un plan para tener soporte completo en una futura generación de plataformas que permitirá al sistema operativo solicitar un % de memoria que se espeje según sus necesidades únicas.

